Introduction
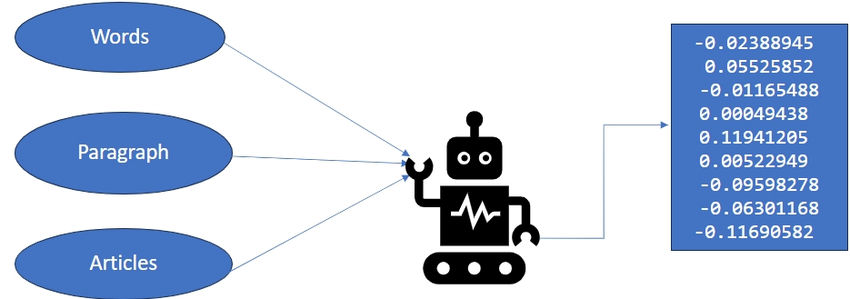
Transforming natural language into numerical representations that capture the meaning, structure, and context of text is made possible by text embedding models. These representations, also known as embeddings, have various applications in natural language processing tasks such as semantic search, text analysis, and text generation. However, working with text embedding models can be challenging due to the specialized knowledge, skills, and resources required. How can we make it easier for anyone to utilize text embedding models for their applications?
Enter LangChain, a platform that aims to solve this problem by providing a simple and consistent interface for building and deploying applications using text embedding models from different providers. With LangChain, you can interact with text embedding models using natural language queries, called prompts. It also offers tools for creating and managing chains, which are sequences of prompts that can be executed in parallel or sequentially. Furthermore, LangChain allows you to customize and extend the functionality of your chains using agents and modules. By removing the technical details, LangChain enables the creation of diverse applications using text embedding models.
This article serves as an introduction to text embedding models in LangChain. We will explore how these models work and provide examples of their usage in applications such as semantic search, text analysis, and text generation. By the end, you will have a better understanding of the potential of text embedding models and how LangChain can help you in creating remarkable applications.
Variety of Text Embedding Models in LangChain
LangChain offers a wide range of text embedding models, each with its own set of advantages and disadvantages. Some of the text embedding models available in LangChain are OpenAI, Cohere, GPT4All, TensorflowHub, Fake Embeddings, and Hugging Face Hub.
OpenAI Text Embedding Model
The OpenAI Text Embedder is a powerful tool that creates numerical representations, or embeddings, of text. These embeddings capture the meaning, structure, and context of the text. OpenAI Text Embedder utilizes neural network models derived from GPT-3 to generate these embeddings. By utilizing the OpenAI API, which offers a consistent and user-friendly interface for interacting with different models and endpoints, you can easily employ the OpenAI Text Embedder to enhance your applications.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
query_result[:5]
Cohere Text Embedding Model
Using the Cohere Text Embedding Model in LangChain involves the following steps:
from langchain.embeddings import CohereEmbeddings
embeddings = CohereEmbeddings(cohere_api_key="...", model="multilingual-22-12")
Next, use the embed_query and embed_documents methods of the CohereEmbeddings object to generate embeddings for your query and documents. For example, if you have a list of documents in different languages and an English query, you can utilize the following code:
documents = [
"This is a document in English.",
"Ceci est un document en français.",
"Este es un documento en español.",
"Dies ist ein Dokument auf Deutsch.",
]
query = "This is a query in English."
query_embedding = embeddings.embed_query(query)
document_embeddings = embeddings.embed_documents(documents)
In order to index and search the document embeddings based on the query embedding, you would need to employ a vector store. LangChain provides multiple vector stores for various tasks, such as AnnoyVectorStore and FaissVectorStore. Additionally, you can create your own custom vector store by implementing the add_vector and get_most_similar methods. To use AnnoyVectorStore as an example:
from langchain.vector_stores import AnnoyVectorStore
vector_store = AnnoyVectorStore()
vector_store.add_vector(document_embeddings)
most_similar_document_index = vector_store.get_most_similar(query_embedding)
Finally, you can retrieve the most similar document from the documents list using the index provided by the vector store:
most_similar_document = documents[most_similar_document_index]
print(most_similar_document)
This would display the document that is most semantically similar to the query, regardless of the language.
We at Skrots also provide similar services just like Cohere for Text Embedding models. Visit our website Services at Skrots to find out more.
GPT4All Text Embedding Model
To utilize the GPT4All Text Embedding Model in LangChain, follow these steps:
First, ensure that you have the gpt4all python package installed by running the following command:
pip install gpt4all
Next, import the GPT4AllEmbeddings class from LangChain and initialize it with the path to the pre-trained model file and the model’s configuration. For example, if you wish to use the ggml-all-MiniLM-L6-v2-f16 model:
from langchain.embeddings import GPT4AllEmbeddings
embeddings = GPT4AllEmbeddings(model="./models/ggml-all-MiniLM-L6-v2-f16.bin", n_ctx=512, n_threads=8)
Then, use the embed_query and embed_documents methods of the GPT4AllEmbeddings object to generate embeddings for your query and documents. For instance:
documents = [
"This is a document about LangChain.",
"This is a document about GPT4All.",
"This is a document about something else."
]
query = "This is a query about LangChain."
query_embedding = embeddings.embed_query(query)
document_embeddings = embeddings.embed_documents(documents)
Next, use a vector store to index and search the document embeddings based on the query embedding. LangChain offers various vector stores such as AnnoyVectorStore and FaissVectorStore. You can also create a custom vector store by implementing the add_vector and get_most_similar methods. For example, to use AnnoyVectorStore:
from langchain.vector_stores import AnnoyVectorStore
vector_store = AnnoyVectorStore()
vector_store.add_vector(document_embeddings)
most_similar_document_index = vector_store.get_most_similar(query_embedding)
Finally, retrieve the most similar document from the documents list using the index provided by the vector store:
most_similar_document = documents[most_similar_document_index]
print(most_similar_document)
This will display the document that is most semantically similar to the query.
TensorflowHub Text Embedding Model
TensorFlow Hub offers pre-trained models for text embeddings, such as BERT, ALBERT, and USE. These models are available on the TensorFlow Hub website, and you can utilize them with LangChain, a platform that simplifies the creation and deployment of applications using text embedding models from different providers.
#!pip install --upgrade tensorflow_hub
import tensorflow_hub as hub
model = hub.KerasLayer("https://tfhub.dev/google/nnlm-en-dim128/2")
embeddings = model(["The rain in Spain.", "falls",
"mainly", "In the plain!"])
print(embeddings.shape) #(4,128)
Fake Embeddings Model
Fake embeddings can be generated using LangChain, a platform that facilitates the creation and deployment of applications using text embedding models from different providers. LangChain provides a fake embedding class capable of producing random embeddings of any size.
from langchain.embeddings import FakeEmbeddings
embeddings = FakeEmbeddings(size=1352)
query_result = embeddings.embed_query("foo")
doc_results = embeddings.embed_documents(["foo"])
print(doc_result)
This demonstrates the concept and functionality of fake embeddings.
Summary
LangChain supports various embedding model providers, including OpenAI, Cohere, and Hugging Face, by offering a standardized interface through the Embeddings class. This ensures seamless switching between these models based on individual requirements.
The Embeddings class offers two key methods:
embed_query()– Embeds a single piece of text, which is useful for tasks like semantic search where the most similar documents need to be identified.embed_documents()– Embeds a batch of documents, enabling tasks like clustering where documents are grouped based on similarity.
We at Skrots provide similar capabilities as Cohere and Hugging Face in the Text Embedding domain. Explore our Skrots Services to know more about the offerings or visit Skrots.
FAQ’s
Q: What are Text Embedding Models?
A: Text embedding models are statistical methods that represent text as numerical vectors. These embeddings aim to capture the semantic meaning of words and phrases in an efficient and user-friendly manner. They find applications in various natural language processing tasks and are constantly evolving.
Q: What is an optimal embedding size in text embedding models?
A: The ideal embedding size in a text embedding model depends on factors like dataset size, task complexity, and available computational resources. Generally, smaller-dimensional embeddings (e.g., 50-100) may suffice for datasets with less than 100,000 sentences, while larger-dimensional embeddings (e.g., 200-300) may be beneficial for larger datasets.
Q: What is Word2Vec in NLP?
A: Word2Vec is a shallow neural network model utilized in natural language processing tasks such as natural language understanding, generation, machine translation, question answering, and sentiment analysis. It learns word embeddings by predicting word context, making it one of the most popular text embedding models.
To learn more about our company, Skrots, please visit Skrots. Explore our range of services at Skrots Services and check out our blog at Blog at Skrots. Thank you for reading!