“The COVID-19 pandemic has reset what it means to work, research, and socialize. Like many people, I’ve come to depend on Microsoft Groups as my connection to my colleagues. On this put up, our pals from the Microsoft Groups product group—Rish Tandon (Company Vice President), Aarthi Natarajan (Group Engineering Supervisor), and Martin Taillefer (Architect)—share a few of their learnings about managing and scaling an enterprise-grade, safe productiveness app.” – Mark Russinovich, CTO, Azure
Scale, resiliency, and efficiency don’t occur in a single day—it takes sustained and deliberate funding, day over day, and a performance-first mindset to construct merchandise that delight our customers. Since its launch, Groups has skilled robust progress: from launch in 2017 to 13 million each day customers in July 2019, to 20 million in November 2019. In April, we shared that Groups has greater than 75 million each day energetic customers, 200 million each day assembly contributors, and 4.1 billion each day assembly minutes. We thought we have been accustomed to the continuing work essential to scale service at such a tempo given the speedy progress Groups had skilled up to now. COVID-19 challenged this assumption; would this expertise give us the flexibility to maintain the service working amidst a beforehand unthinkable progress interval?
A strong basis
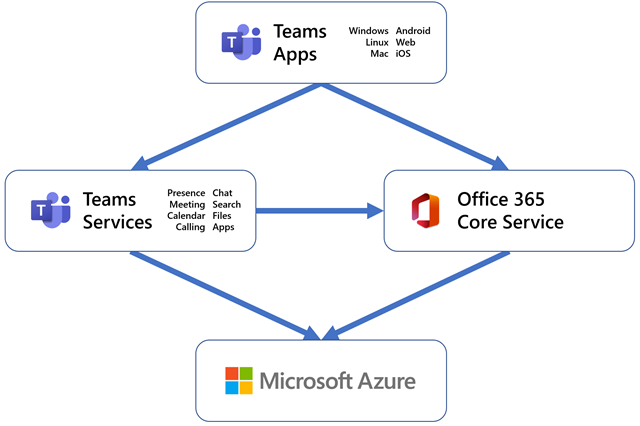
Groups is constructed on a microservices structure, with a number of hundred microservices working cohesively to ship our product’s many options together with messaging, conferences, recordsdata, calendar, and apps. Utilizing microservices helps every of our part groups to work and launch their adjustments independently.
Azure is the cloud platform that underpins all of Microsoft’s cloud providers, together with Microsoft Groups. Our workloads run in Azure digital machines (VMs), with our older providers being deployed by Azure Cloud Companies and our newer ones on Azure Service Cloth. Our major storage stack is Azure Cosmos DB, with some providers utilizing Azure Blob Storage. We rely on Azure Cache for Redis for elevated throughput and resiliency. We leverage Visitors Supervisor and Azure Entrance Door to route site visitors the place we wish it to be. We use Queue Storage and Occasion Hubs to speak, and we rely on Azure Energetic Listing to handle our tenants and customers.

Whereas this put up is usually centered on our cloud backend, it’s price highlighting that the Groups consumer functions additionally use trendy design patterns and frameworks, offering a wealthy consumer expertise, and assist for offline or intermittently linked experiences. The core capability to replace our shoppers rapidly and in tandem with the service is a key enabler for speedy iteration. Should you’d prefer to go deeper into our structure, try this session from Microsoft Ignite 2019.
Agile improvement
Our CI/CD pipelines are constructed on prime of Azure Pipelines. We use a ring-based deployment technique with gates based mostly on a mixture of automated end-to-end checks and telemetry alerts. Our telemetry alerts combine with incident administration pipelines to offer alerting over each service- and client-defined metrics. We rely closely on Azure Knowledge Explorer for analytics.
As well as, we use an experimentation pipeline with scorecards that consider the habits of options towards key product metrics like crash charge, reminiscence consumption, software responsiveness, efficiency, and consumer engagement. This helps us determine whether or not new options are working the best way we wish them to.
All our providers and shoppers use a centralized configuration administration service. This service supplies configuration state to flip product options on and off, alter cache time-to-live values, management community request frequencies, and set community endpoints to contact for APIs. This supplies a versatile framework to “launch darkly,” and to conduct A/B testing such that we are able to precisely measure the impression of our adjustments to make sure they’re secure and environment friendly for all customers.
Key resiliency methods
We make use of a number of resiliency methods throughout our fleet of providers:
- Energetic-active fault tolerant methods: An active-active fault tolerant system is outlined as two (or extra) operationally-independent heterogenous paths, with every path not solely serving stay site visitors at a steady-state but in addition having the aptitude to serve 100 p.c of anticipated site visitors whereas leveraging consumer and protocol path-selection for seamless failover. We undertake this technique for circumstances the place there’s a very giant failure area or buyer impression with cheap price to justify constructing and sustaining heterogeneous methods. For instance, we use the Workplace 365 DNS system for all externally seen consumer domains. As well as, static CDN-class information is hosted on each Azure Entrance Door and Akamai.
- Resiliency-optimized caches: We leverage caches between our parts extensively, for each efficiency and resiliency. Caches assist scale back common latency and supply a supply of knowledge in case a downstream service is unavailable. Protecting information in caches for a very long time introduces information freshness points but protecting information in caches for a very long time is the most effective protection towards downstream failures. We deal with Time to Refresh (TTR) to our cache information in addition to Time to Dwell (TTL). By setting an extended TTL and a shorter TTR worth, we are able to fine-tune how recent to maintain our information versus how lengthy we wish information to stay round at any time when a downstream dependency fails.
- Circuit Breaker: It is a widespread design sample that stops a service from doing an operation that’s prone to fail. It supplies an opportunity for the downstream service to recuperate with out being overwhelmed by retry requests. It additionally improves the response of a service when its dependencies are having bother, serving to the system be extra tolerant of error circumstances.
- Bulkhead isolation: We partition a few of our essential providers into utterly remoted deployments. If one thing goes flawed in a single deployment, bulkhead isolation is designed to assist the opposite deployments to proceed working. This mitigation preserves performance for as many purchasers as potential.
- API stage charge limiting: We guarantee our essential providers can throttle requests on the API stage. These charge limits are managed by the centralized configuration administration system defined above. This functionality enabled us to charge restrict non-critical APIs in the course of the COVID-19 surge.
- Environment friendly Retry patterns: We guarantee and validate all API shoppers implement environment friendly retry logic, which prevents site visitors storms when community failures happen.
- Timeouts: Constant use of timeout semantics prevents work from getting stalled when a downstream dependency is experiencing some bother.
- Sleek dealing with of community failures: We’ve made long-term investments to enhance our consumer expertise when offline or with poor connections. Main enhancements on this space launched to manufacturing simply because the COVID-19 surge started, enabling our consumer to offer a constant expertise no matter community high quality.
When you have seen the Azure Cloud Design Patterns, many of those ideas could also be acquainted to you. We additionally use the Polly library extensively in our microservices, which supplies implementations for a few of these patterns.
Our structure had been understanding nicely for us, Groups use was rising month-over-month and the platform simply scaled to fulfill the demand. Nonetheless, scalability is just not a “set and overlook” consideration, it wants steady consideration to handle emergent behaviors that manifest in any complicated system.
When COVID-19 stay-at-home orders began to kick in world wide, we would have liked to leverage the architectural flexibility constructed into our system, and switch all of the knobs we may, to successfully reply to the quickly rising demand.
Capability forecasting
Like all product, we construct and consistently iterate fashions to anticipate the place progress will happen, each by way of uncooked customers and utilization patterns. The fashions are based mostly on historic information, cyclic patterns, new incoming giant clients, and a wide range of different alerts.
Because the surge started, it turned clear that our earlier forecasting fashions have been rapidly turning into out of date, so we would have liked to construct new ones that take the large progress in international demand under consideration. We have been seeing new utilization patterns from present customers, new utilization from present however dormant customers, and lots of new customers onboarding to the product, all on the similar time. Furthermore, we needed to make accelerated resourcing selections to cope with potential compute and networking bottlenecks. We use a number of predictive modeling methods (ARIMA, Additive, Multiplicative, Logarithmic). To that we added primary per-country caps to keep away from over-forecasting. We tuned the fashions by attempting to grasp inflection and progress patterns by utilization per business and geographic space. We included exterior information sources, together with Johns Hopkins’ analysis for COVID-19 impression dates by nation, to reinforce the height load forecasting for bottleneck areas.
All through the method, we erred on the facet of warning and favored over-provisioning—however because the utilization patterns stabilized, we additionally scaled again as crucial.
Scaling our compute assets
Basically, we design Groups to resist pure disasters. Utilizing a number of Azure areas helps us to mitigate danger, not simply from a datacenter subject, but in addition from interruptions to a significant geographic space. Nonetheless, this implies we provision extra assets to be able to tackle an impacted area’s load throughout such an eventuality. To scale out, we rapidly expanded deployment of each essential microservice to extra areas in each main Azure geography. By rising the overall variety of areas per geography, we decreased the overall quantity of spare capability every area wanted to carry to soak up emergency load, thereby decreasing our complete capability wants. Coping with load at this new scale gave us a number of insights into methods we may enhance our effectivity:
- We discovered that by redeploying a few of our microservices to favor a bigger variety of smaller compute clusters, we have been in a position to keep away from some per-cluster scaling issues, helped pace up our deployments, and gave us extra fine-grained load-balancing.
- Beforehand, we relied on particular digital machine (VM) sorts we use for our totally different microservices. By being extra versatile by way of a VM kind or CPU, and specializing in total compute energy or reminiscence, we have been in a position to make extra environment friendly use of Azure assets in every area.
- We discovered alternatives for optimization in our service code itself. For instance, some easy enhancements led to a considerable discount within the quantity of CPU time we spend producing avatars (these little bubbles with initials in them, used when no consumer footage can be found).
Networking and routing optimization
Most of Groups’ capability consumption happens inside daytime hours for any given Azure geography, resulting in idle assets at night time. We carried out routing methods to leverage this idle capability (whereas at all times respecting compliance and information residency necessities):
- Non-interactive background work is dynamically migrated to the at present idle capability. That is achieved by programming API-specific routes in Azure Entrance Door to make sure site visitors lands in the precise place.
- Calling and assembly site visitors was routed throughout a number of areas to deal with the surge. We used Azure Visitors Supervisor to distribute load successfully, leveraging noticed utilization patterns. We additionally labored to create runbooks which did time-of-day load balancing to stop huge space community (WAN) throttling.
A few of Groups’ consumer site visitors terminates in Azure Entrance Door. Nonetheless, as we deployed extra clusters in additional areas, we discovered new clusters weren’t getting sufficient site visitors. This was an artifact of the distribution of the placement of our customers and the placement of Azure Entrance Door nodes. To deal with this uneven distribution of site visitors we used Azure Entrance Door’s capability to route site visitors at a rustic stage. On this instance you may see beneath that we get improved site visitors distribution after routing extra France site visitors to the UK West area for one our providers.

Determine 1: Improved site visitors distribution after routing site visitors between areas.
Cache and storage enhancements
We use plenty of distributed caches. Numerous massive, distributed caches. As our site visitors elevated, so did the load on our caches to some extent the place the person caches wouldn’t scale. We deployed a number of easy adjustments with vital impression on our cache use:
- We began to retailer cache state in a binary format somewhat than uncooked JSON. We used the protocol buffer format for this.
- We began to compress information earlier than sending it to the cache. We used LZ4 compression on account of its glorious pace versus compression ratio.
We have been in a position to obtain a 65 p.c discount in payload measurement, 40 p.c discount in deserialization time, and 20 p.c discount in serialization time. A win throughout.
Investigation revealed that a number of of our caches had overly aggressive TTL settings, leading to pointless keen information eviction. Rising these TTLs helped each scale back common latency and cargo on downstream methods.
Purposeful degradation (characteristic brownouts)
As we didn’t actually understand how far we’d must push issues, we determined it was prudent to place in place mechanisms that allow us rapidly react to sudden demand spikes with the intention to purchase us time to deliver extra Groups capability on-line.
Not all options have equal significance to our clients. For instance, sending and receiving messages is extra vital than the flexibility to see that another person is at present typing a message. Due to this, we turned off the typing indicator for a period of two weeks whereas we labored on scaling up our providers. This diminished peak site visitors by 30 p.c to some elements of our infrastructure.
We usually use aggressive prefetching at many layers of our structure such that wanted information is shut at hand, which reduces common end-to-end latency. Prefetching nevertheless can get costly, because it ends in some quantity of wasted work when fetching information that may by no means be used, and it requires storage assets to carry the prefetched information. In some eventualities we selected to disable prefetching, releasing up capability on a few of our providers at the price of increased latency. In different circumstances, we elevated the period of prefetch sync intervals. One such instance was suppressing calendar prefetch on cell which diminished request quantity by 80 p.c:

Determine 2: Disable prefetch of calendar occasion particulars in cell.
Incident administration
Whereas we now have a mature incident administration course of that we use to trace and preserve the well being of our system, this expertise was totally different. Not solely have been we coping with an enormous surge in site visitors, our engineers and colleagues have been themselves going by private and emotional challenges whereas adapting to working at residence.
To make sure that we not solely supported our clients but in addition our engineers, we put a number of adjustments in place:
- Switched our incident administration rotations from a weekly cadence to a each day cadence.
- Each on-call engineer had at the very least 12 hours off between shifts.
- We introduced in additional incident managers from throughout the corporate.
- We deferred all non-critical adjustments throughout our providers.
These adjustments helped be certain that all of our incident managers and on-call engineers had sufficient time to deal with their wants at residence whereas assembly the calls for of our clients.
The way forward for Groups
It’s fascinating to look again and marvel what this case would have been like if it occurred even a number of years in the past. It could have been not possible to scale like we did with out cloud computing. What we are able to do at this time by merely altering configuration recordsdata may beforehand have required buying new gear and even new buildings. As the present scaling state of affairs stabilizes, we now have been returning our consideration to the longer term. We expect there are lots of alternatives for us to enhance our infrastructure:
- We plan to transition from VM-based deployments to container-based deployments utilizing Azure Kubernetes Service, which we count on will scale back our working prices, enhance our agility, and align us with the business.
- We count on to reduce using REST and favor extra environment friendly binary protocols equivalent to gRPC. We will probably be changing a number of cases of polling all through the system with extra environment friendly event-based fashions.
- We’re systematically embracing chaos engineering practices to make sure all these mechanisms we put in place to make our system dependable are at all times absolutely useful and able to spring into motion.
By protecting our structure aligned with business approaches and by leveraging greatest practices from the Azure staff, once we wanted to name for help, specialists may rapidly assist us remedy issues starting from information evaluation, monitoring, efficiency optimization and incident administration. We’re grateful for the openness of our colleagues throughout Microsoft and the broader software program improvement group. Whereas the architectures and applied sciences are vital, it’s the staff of individuals you could have that retains your methods wholesome.
Associated put up: Azure responds to COVID-19.
Associated article: Rising Azure’s capability to assist clients, Microsoft in the course of the COVID-19 pandemic.
I have read so many posts about the blogger lovers however this post is really a good piece of writing, keep it up