How To View Knowledge Movement Execution Plan In Azure Knowledge Manufacturing unit
Introduction
On this article, we’ll discover methods to view Knowledge move execution plan utilizing Azure Knowledge Manufacturing unit. The execution plan offers partition and efficiency metrics for the info engineers or operation group for evaluate. This significant step permits builders to make sure that efficiency targets are met.
Challenges
In our earlier article, we created a pipeline utilizing Mapping Knowledge move. Now, we have to evaluate the time it took to remodel the info and construct a greater understanding of the place we are able to optimize our resolution.
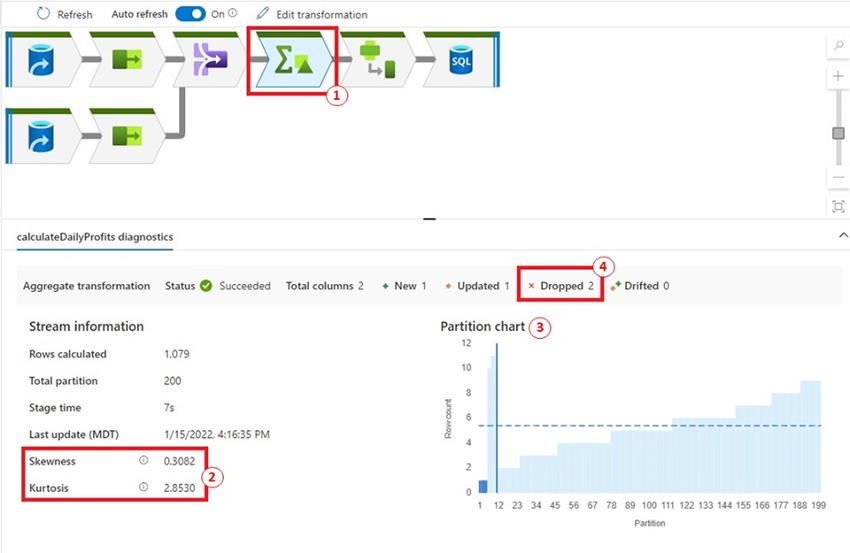
Azure Knowledge Manufacturing unit Monitor offers this functionality for us. That is accessible for debugging and scheduled pipelines. Earlier than we dive into the tutorial, we have to perceive four key ideas:
- Stage: A Mapping information move pipeline is damaged up into completely different levels. A stage consists of a bunch of actions that may be executed collectively.
- Partition: A dataset is break up into a number of chunks so it may be processed in parallel. Every chunk is represented as a partition.
- Skewness: Skewness measures how the info is evenly distributed the dataset is. In information move, the perfect vary is between -Three and three.
- Kurtosis: Kurtosis measures what number of outliers is within the dataset. A excessive kurtosis worth means it has heavy outliers. In information move, the perfect worth is lower than 10.
Tutorial
-
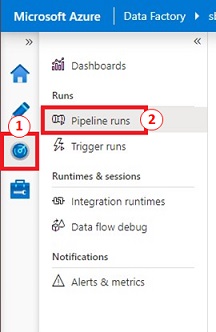
In Azure Knowledge Manufacturing unit Studio, click on on ‘Monitor’. Beneath ‘Runs’, click on on ‘Pipeline runs’.
-
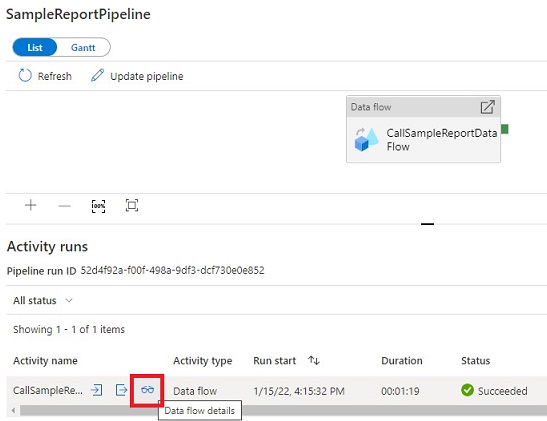
Choose the pipeline and click on on the ‘eye glasses icon’ below ‘Exercise runs’.
-
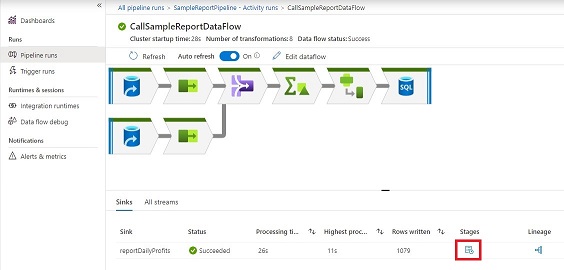
Now, we see the info move. Click on on ‘Phases’ to see how lengthy every stage took. A ‘Phases’ aspect panel will likely be proven.
-
Let’s look at the completely different levels we’ve got:
-
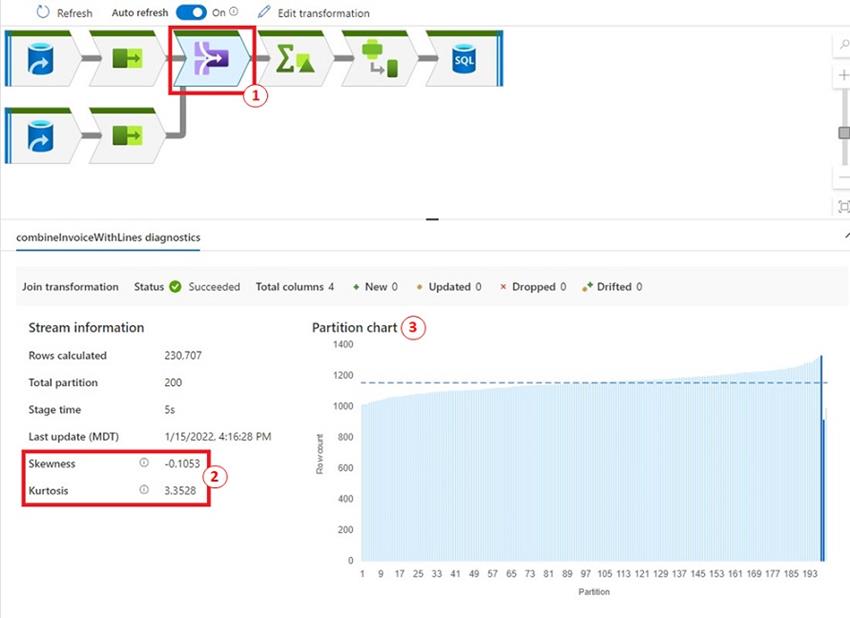
Let’s dive into the ‘Be part of transformation’ by clicking on the Be part of icon. We noticed that:
- The very first thing we discover is each Skewness and Kurtosis are throughout the vary specified within the Challenges part.
- The ‘Partition chart’ exhibits many of the partitions are starting from 1000 to only below 1200 data. The previous few partitions have a under common of data.
Abstract
In abstract, it is extremely vital to evaluate the execution plan of the Mapping information move. With Azure Knowledge Manufacturing unit Monitor, we are able to look at every information move exercise on information adjustments, Skewness, Kurtosis, and the variety of rows for every partition. This data allows us to optimize our pipeline when required.
Lastly, bear in mind to activate verbose logging within the Knowledge move exercise to generate all of the monitoring particulars. This can have some efficiency affect however with out this data, it is going to be troublesome to determine the place the difficulty is.
Completely satisfied Studying!
References