In continuation to our earlier article on Azure Synapse Analytics, we’ll deep dive into the sharding patterns(distributions) which might be used within the Devoted SQL Pool. Within the background, the Dedicate SQL Pool divides work into 60 smaller queries which shall be run in parallel in your compute node. You’ll outline the distribution methodology whereas creating the desk or the ROUND-ROBIN distribution shall be chosen as a default in the event you fail to pick something.
There are three kinds of distribution current
- HASH
- ROUND-ROBIN
- REPLICATED TABLES
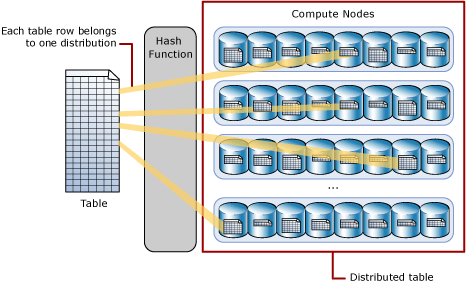
HASH Distribution
Hash distribution is each time the information is saved into the compute nodes from the desk, there is a component referred to as ‘Hash Operate’ which takes over the duty to determine which row needs to be saved by which node. It’s the decider which determines the sample of storing all the desk rows. The Hash distribution is the quite common and go-to methodology if you’d like highest question efficiency when querying giant tables for joins and aggregations. Within the background the Hash perform makes use of the values of the declared distribution column to assign every row to the compute nodes.
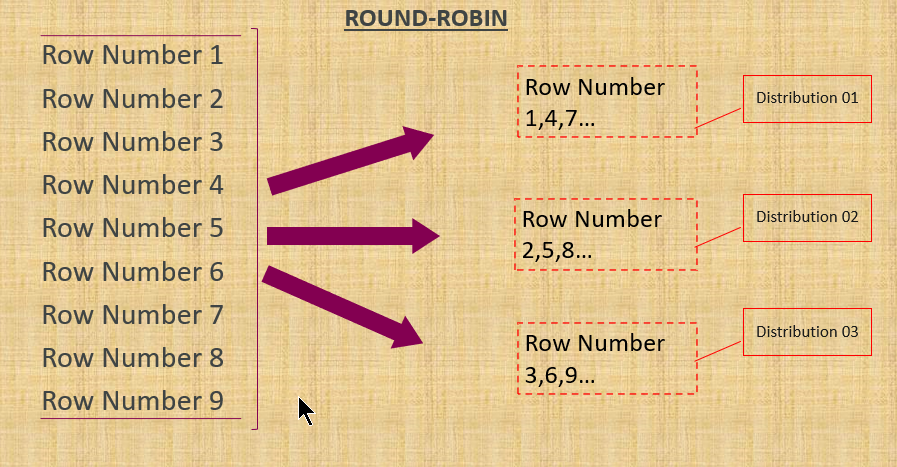
ROUND-ROBIN Distribution
Spherical robin distribution is often used when utilizing as a staging desk for masses and may be very easy sort. It really works in a round style and all of the desk rows shall be positioned into every nodes in a sequential sample. It is rather fast to load information right into a Spherical Robin desk however efficiency of the question shall be higher with Hash distributed tables. The reason being because of the joins which requires reshuffling of the information, therefore the extra time taken for throwing outcomes out.
CREATE TABLE schema_name.table_name
(
{ column_name <data_type> [ <column_options> ] } [ ,...n ]
)
[ WITH ( <table_option> [ ,...n ] ) ]
DISTRIBUTION = REPLICATE -- default for Parallel Information Warehouse
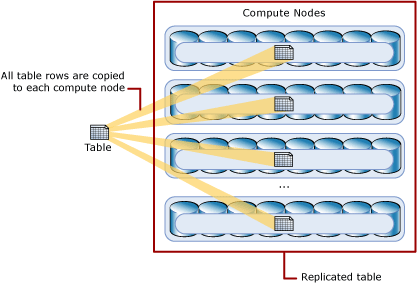
REPLICATED TABLES Distribution
If you’re questioning if there are any strategies that would assist to take care of small or medium tables as virtually not all of the desk we’re going to retailer should be humungous. REPLICATED TABLES offers the quickest and finest question efficiency in the case of working with smaller tables. It does this by caching a full copy of the desk on every compute node which avoids the necessity for information switch among the many nodes earlier than a be a part of or aggregation. It’s generally finest utilized with smaller tables however there shall be additional storage required and there may be an extra overhead that needs to be incurred when writing the information which is why it’s not suggested for use bigger tables.
Abstract
It is a continuation of my earlier article, Azure Synapse Analytics structure. Each the articles explains how the fundamental row information from the tables are saved into the storage and the way the person can manipulate it to get higher efficiency.
Reference:
Microsoft official documentation