Azure Synapse SQL is a know-how which resides contained in the Synapse workspace. Completely we’ve got two swimming pools which we’ve got mentioned intimately in one among our articles few weeks in the past.
- Devoted SQL Pool
- Serverless SQL Pool
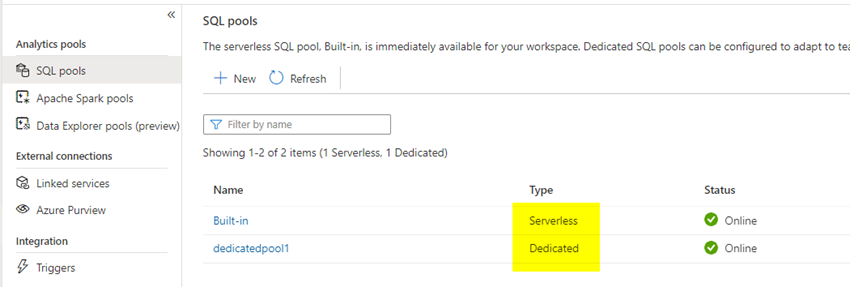
The built-in ‘Serverless SQL Pool’ will get created routinely if you create the workspace and the ‘Devoted SQL Pool’ is the one which the consumer creates. The ‘Devoted SQL Pool’ which was previously known as as Azure DataWarehousing, creates a database within the backend which will probably be seen from Information tab on the left facet pane. So remember the fact that everytime you create a devoted SQL pool you’re additionally making a database within the backend.
The foremost distinction between the 2 swimming pools is the price effectiveness. The serverless SQL pool works primarily based on ‘Pay what you utilize’ methodology, which implies you need to pay just for the assets you utilize if you run the question accessing knowledge from ADLS gen2 or Blob storages and also you incur no different fees. Whereas within the devoted SQL pool, you’ll have devoted assets created for you want database and the run-time engine. The compute energy is outlined as DWU(knowledge warehousing items) and you need to choose it when creating the devoted SQL pool. DWU is compute energy engine which runs the queries and processes the information and the Database created by devoted SQL pool is the storage.
Once you attempt to ingest knowledge right into a devoted SQL pool database, the synapse structure will retailer the information in a distributed vogue. The info will get partitioned into a number of distributions after which saved to optimize efficiency.
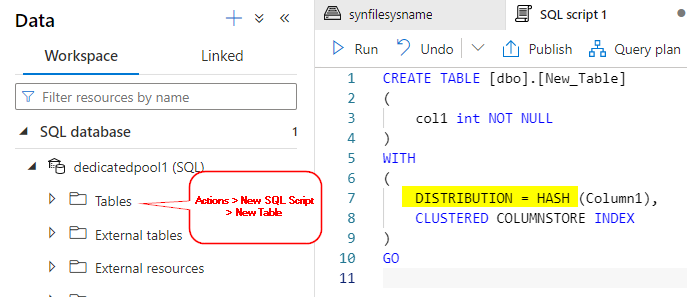
Completely there are three kinds of sharding patterns obtainable in synapse SQL…
- Hash
- Spherical Robin
- Replicate
You may specify which distribution sample you want when creating a brand new desk. I’ve scripted the question to indicate how the distribution parameter will look.
Mainly, Synapse SQL makes use of node-based structure. The ‘Management Node’ acts as a central system of the synapse SQL structure. It’s the entry level for all of the requests and processes made to the synapse and is frequent for each Devoted and Serverless SQL pool fashions.
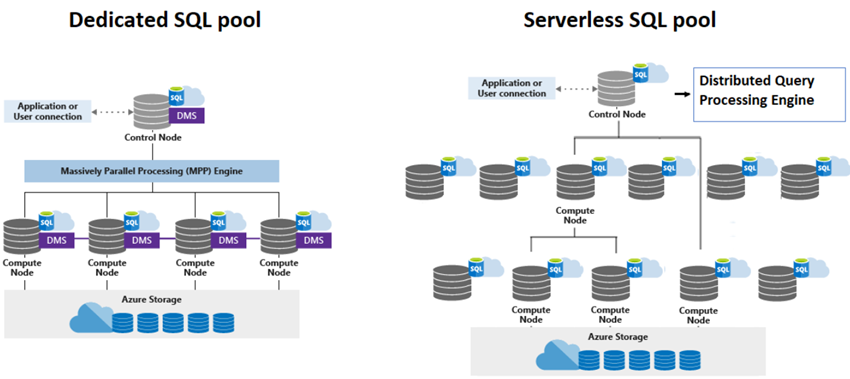
The Devoted SQL Pool follows true MPP (Massively Parallel Processing) structure. It collects the queries submitted to it, transforms them into parallel queries and every question is then handed on to compute nodes. As soon as the question executions are accomplished by all the distributions /compute nodes, the information needs to be collected to current a single end result output. To carry out this devoted SQL pool deploys the DMS (Information Motion Service) which strikes the information between the compute nodes after which the only unit of output is offered.
In Serverless SQL Pool, the queries will probably be divided into a number of duties and assigned into many compute nodes which can make the most of azure storage to course of that knowledge. Much like DMS within the devoted SQL pool, that is carried out achieved by an inner characteristic known as DQP (Distributed Question Processing Engine) which breaks down the larger queries into a number of small duties.
Abstract
Hope this brings fundamental understanding of how azure synapse analytics works behind the scenes. This can present you solutions on how the synapse processes the information in an optimized and efficient method and but so shortly. Extra subjects to return, keep tuned!
Reference
- Microsoft official documentation