This text is a continuation of Half 1 which I posted earlier. I strongly suggest you to undergo half 1 earlier than you undergo this text. The demo we’re going to see will use apache Spark serverless pool mannequin the place we might be loading a parquet pattern knowledge file into spark database (sure, we are going to create a database as nicely) after which analyze the identical utilizing spark from azure notebooks.
The pattern parquet file used could be downloaded from the beneath hyperlink.
To begin with, ensure you have uploaded the pattern file into the ADLS storage. You’ll be able to discuss with my earlier articles in order for you assist or you probably have any doubt on the best way to create a workspace, connect and knowledge lake storage to it and add a file. For this demo, I’ve uploaded the pattern NYCTripSmall.parquet file beneath the container of my ADLS storage.
Subsequent step is to create a Serverless Spark Pool. I’d not be going by that as I’ve already lined it in my earlier articles.
Analyze pattern knowledge with spark pool
As a primary step we’re going to load the pattern knowledge file from storage into spark dataframe utilizing PySpark code. The scripts might be executed within the cells current within the pocket book and it presents help for a lot of languages like PySpark, .internet(c#), scala and many others., so that you can run your question.
Go to improvement tab and choose new Pocket book. That is the place we are going to see the cells as knowledgeable earlier and we have now execute the codes.
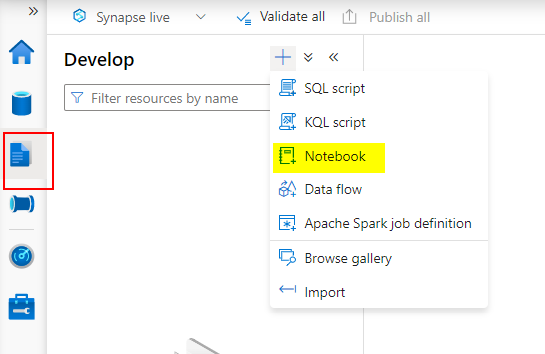
You can not run the question with out deciding on the spark pool useful resource. You will discover the checklist of spark swimming pools out there within the dropdown to pick out.
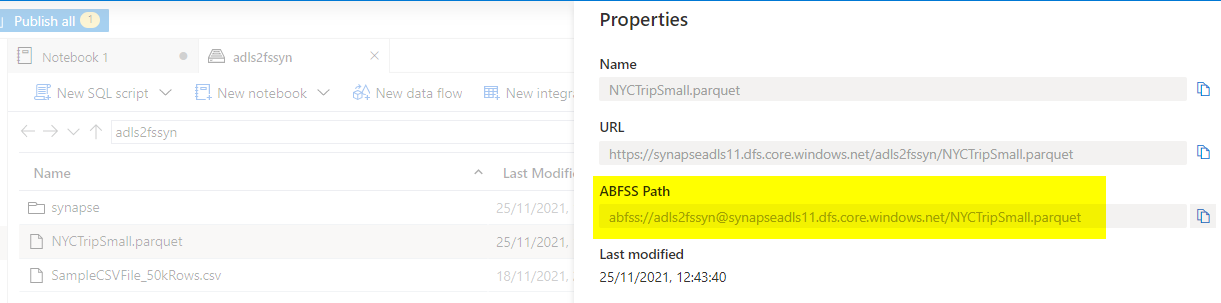
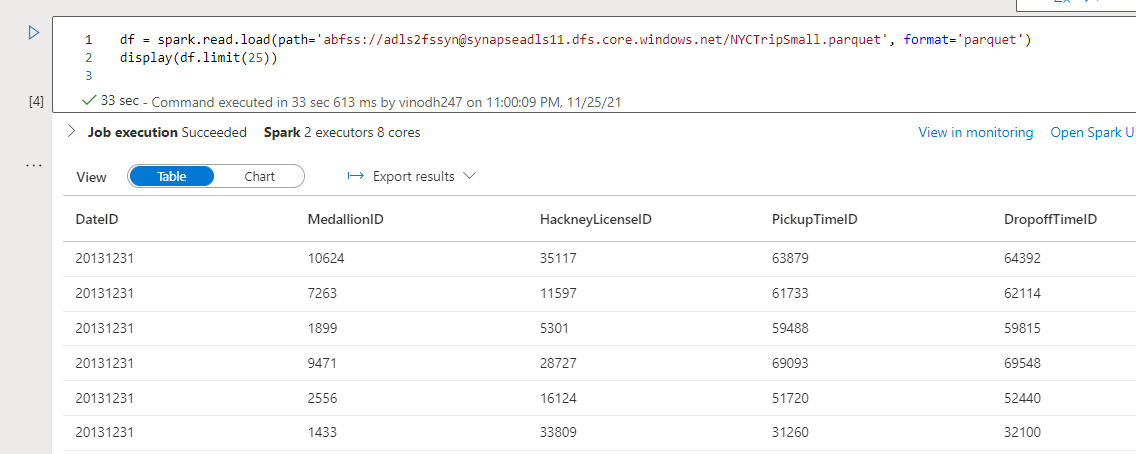
I’m utilizing the next code to load the pattern file into an information body and show the primary 25 rows. The trail you may get is from the pattern file properties à ABFSS Path (azure blob file system path)
df = spark.learn.load(path=’abfss://adls2fssyn@synapseadls11.dfs.core.home windows.internet/NYCTripSmall.parquet’, format=’parquet’)
show(df.restrict(25))
As soon as after you hit the execute button. Please be aware that it’ll take time to see the outcomes as it’s first time execution. The next runs may even see improved outcomes.
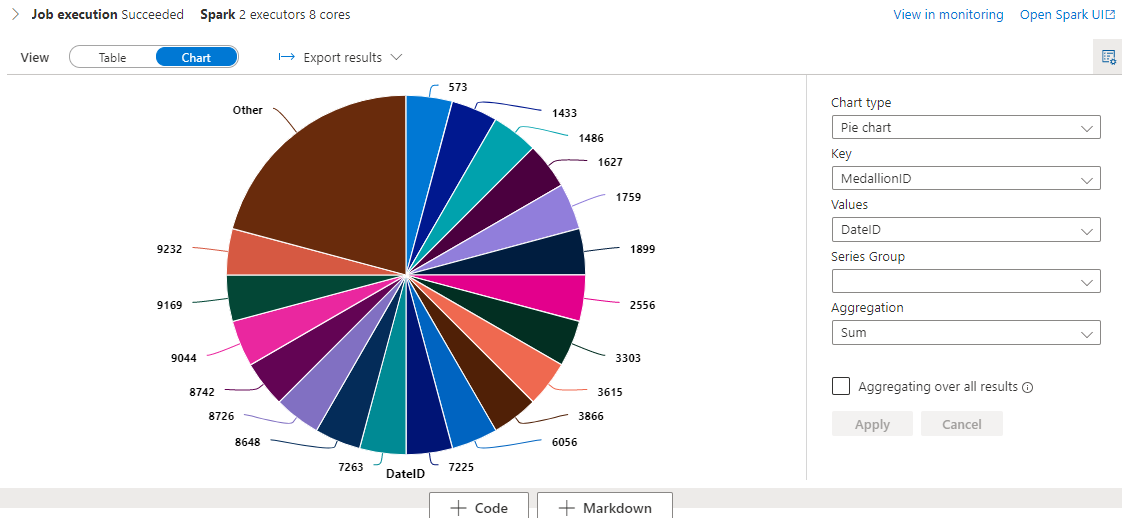
And as common azure synapse studio compliments you with chart characteristic which you could play with.
What if we might load the newly created Dataframe right into a database? Right into a desk contained in the database? Let’s see how can we try this.
I run one other PySpark question of two strains which is able to create database and cargo the dataframe that we created within the earlier step into desk inside that database.
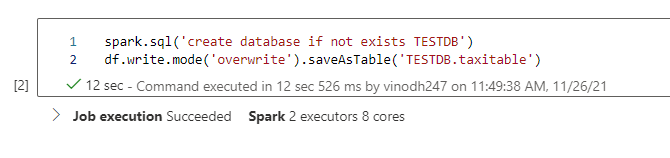
The question has been executed efficiently. Now go to the information desk on left aspect and refresh the workspace tab to see the newly created database and the desk.
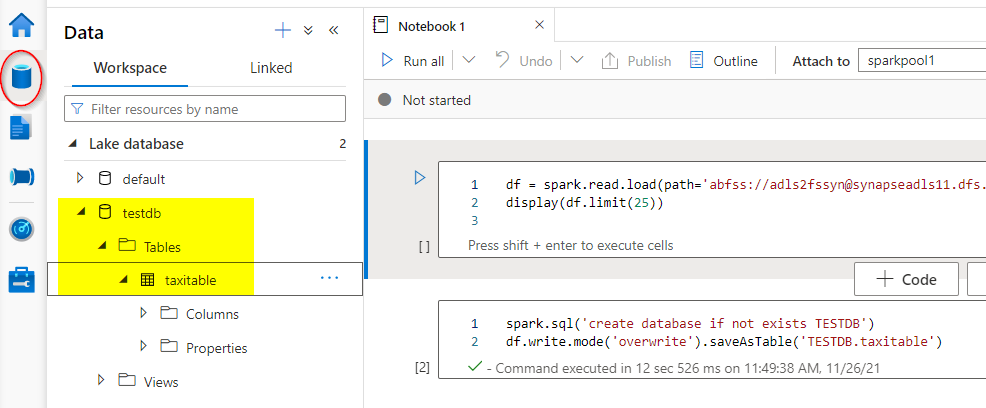
Analyzing the information
Now let’s analyze the saved knowledge utilizing PySpark. I’m going to drag down all the information within the desk and put it aside into a brand new dataframe.
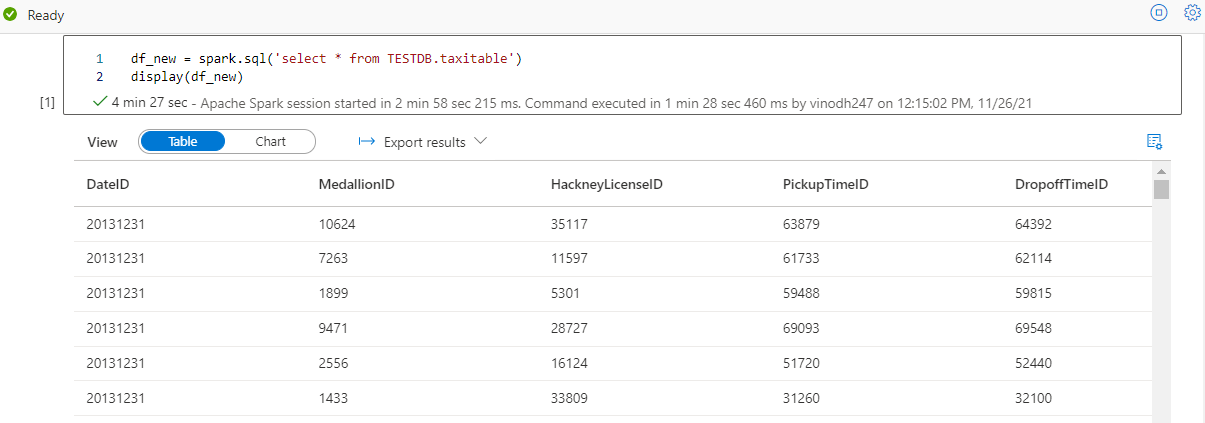
Let’s do some aggregations into our newly created desk and save the outcomes as a brand new desk name passengercountstats.
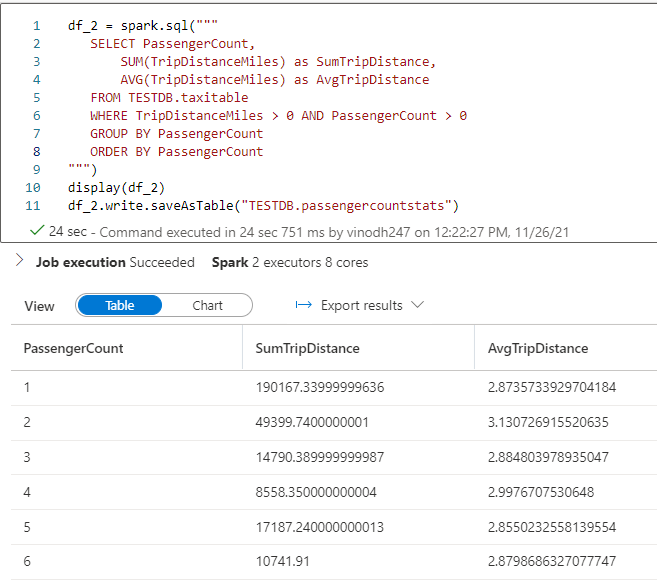
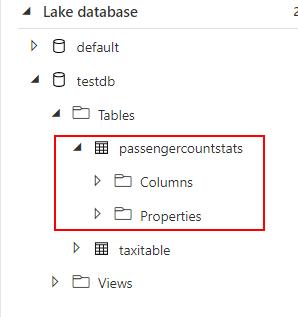
As knowledgeable earlier the outcomes could be interpreted with the built-in chart sorts for visualization.
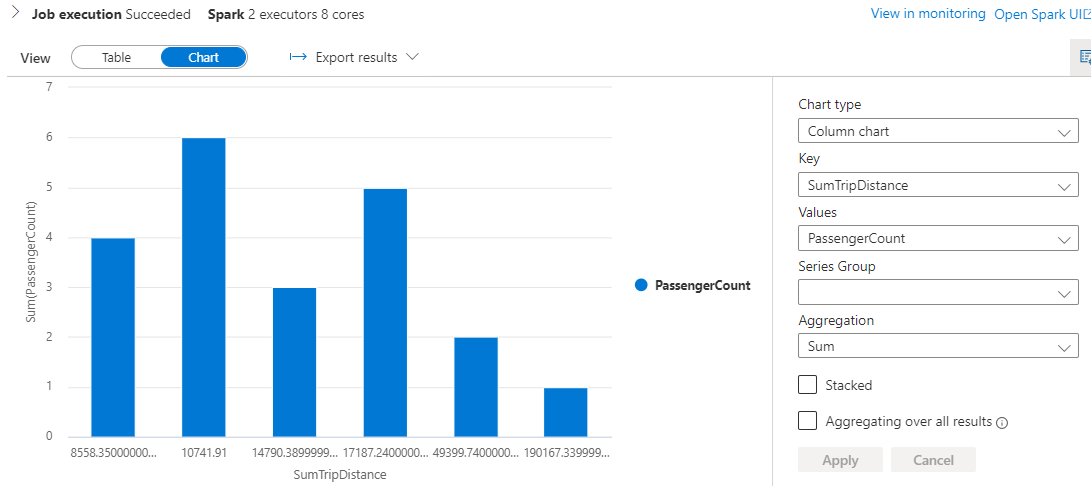
Abstract
On this two half article, we noticed what’s Spark and what are its essential ideas. Find out how to load a parquet file into ADLS and question them utilizing serverless spark by synapse studio after which to create a spark database and cargo tables into it from the dataframe. We additionally noticed the best way to interpret the desk outcomes visually right into a bar chart or pie chart with none addons or exterior purposes.
References
Microsoft official documentation.