That is the half one article of the 2 half sequence with demo which explains analyzing information with spark pool in azure synapse analytics. Because the matter touches apache spark closely, I’ve determined to put in writing a devoted article to clarify apache spark in azure -hence this half one. Pls make certain to learn half two as nicely for an entire understanding.
Apache Spark in Azure Synapse Analytics
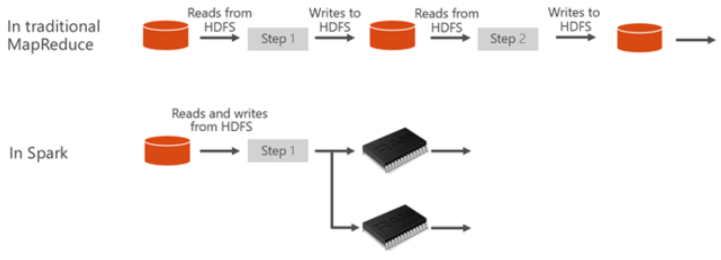
Apache spark is an open supply in-memory framework and an information processing engine to retailer and course of information real-time from a number of cluster computer systems in a simplified approach. It principally can load the information into the reminiscence for frequent queries which helps in quicker outcomes than the conventional disk-based reads. Azure enables you to create and configure serverless Apache Spark pool simply and the spark swimming pools in Azure Synapse are appropriate with Azure storage and Azure information lake gen2 storage via which you’ll course of the information which can be saved in Azure.
Usually in Azure Databricks we are going to create the spark clusters which is able to run the notebooks however in Azure Synapse analytics we gained’t create cluster as an alternative we are going to create spark pool. Spark swimming pools to outline, are nothing however absolutely managed spark service. It has many benefits like velocity, effectivity, ease of utilization and so on., to call a number of. When creating the spark pool, we now have to outline the variety of nodes and the sizes of every and so on., put up which the spark pool will likely be executing the pocket book. Although we are going to set the variety of min and max nodes, it’s the spark pool which is able to determine what number of variety of nodes that it ought to use based mostly on the duty execution, we won’t be having any management over it.
Creating Apache Spark Pool
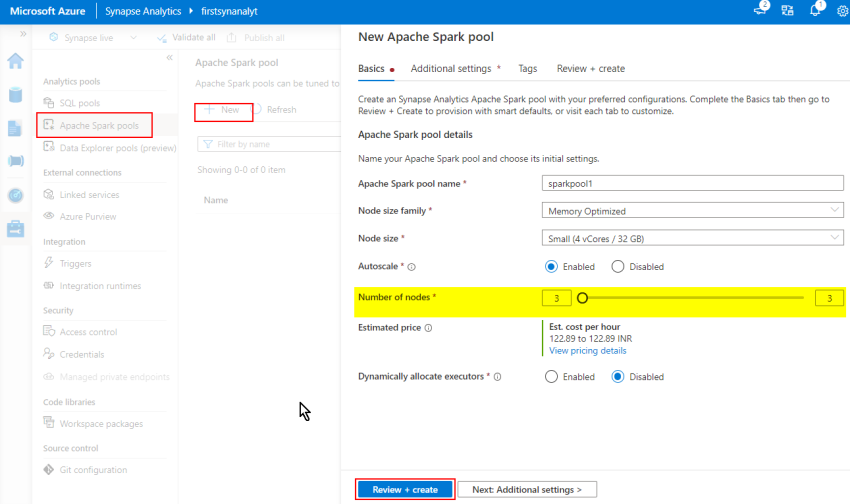
Serverless spark pool is just like serverless SQL pool (refer my earlier article which explains the distinction between Serverless and Devoted swimming pools in azure synapse analytics) you’ll solely pay for the nodes which can be getting consumed for the question you run. In the event you created the nodes and didn’t run something (not utilized), you’ll not be charged any cloud value. On the within, principally the serverless spark pool will create an Spark session based mostly on the requirement which is able to run your code. Additionally, you will have an choice to auto-pause the spark pool after some idle minutes.
Apache spark naturally helps many languages likes Scala, Java, Python and R with Python and Scala having interactive shells (PySpark and spark-shell). That is very worthwhile for the opposite companies inside Synapse analytics to eat the big volumes of knowledge processed by Apache Spark. Apache Spark additionally has machine studying library constructed on prime of it for the customers to entry it throughout the Synapse Spark Pool. This may be mixed with the inbuilt assist for the notebooks to set and create machine studying functions in Apache Spark.
References
Microsoft official documentation