Using Langchain to Enhance an OpenAI Bot with Chat and Source Retrieval
Introduction
In my previous article about Langchain and Python, I introduced a chatbot to our customers. However, they expressed a desire for a real chat functionality similar to Chat-GPT. This would provide several advantages, including the ability to refine questions, clarify misunderstandings, and get better results. Additionally, it would be great to display the sources used in the responses. These requests were completely reasonable, and I love a good challenge, so I spent my weekend trying to fulfill them.
What’s Required?
The first part of the work, the embedding process, remains almost unchanged. This involves breaking down the documentation into smaller fragments, generating vectors that represent their semantic meaning, and storing them in a vector database. This allows us to retrieve the most appropriate parts of the documentation to provide context for the questions. If you want to learn more about this process, I recommend reading the article I mentioned in the introduction.
However, I made a slight change. To link the sources later on, I now only use content that I load from our documentation portal and other sources via the sitemap. This way, the sources can be displayed as clickable links.
I also added practical parameters to the routine that loads content from a sitemap. Our Langchain class supports post-processing of the crawled HTML content, allowing us to remove annoying or unnecessary elements like navigation, headers, and footers before the embedding process. It looks something like this:
def sanitize_documentx_page(content: BeautifulSoup) -> str:
# Find content div element
div_element = content.find('div', {"class": "i-body-content"})
return str(div_element)
def add_sitemap_documents(web_path, filter_urls, parsing_function, instance):
if os.path.isfile(web_path):
# If it's a local file path, use the SitemapLoader with is_local=True
loader = SitemapLoader(web_path=web_path, filter_urls=filter_urls, parsing_function=parsing_function, is_local=True)
else:
# If it's a web URL, use the SitemapLoader with web_path
loader = SitemapLoader(web_path=web_path, filter_urls=filter_urls, parsing_function=parsing_function)
loader.session.headers["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36"
add_documents(loader, instance)
# add EN .NET help from docu.combit.net
add_sitemap_documents('C:DocBotinputsitemap_net_en.xml',
[],
sanitize_documentx_page,
instance)
Changes to the Server
The more significant and complex part of the changes involves the server. Different APIs need to be called, and the session state must be saved for subsequent calls. Let’s break it down step by step.
Session Handling
Flask handles session handling quite efficiently. However, only JSON serializable objects can be included in the session. To work around this limitation, I created a local store for the necessary objects and used generated GUIDs to identify the session. You can find more details about this in the sources I’ve linked below. While this solution is not a stroke of genius, it serves the purpose for now. In a production environment, a more elegant solution would be implemented.
Storing the History
Unlike the simple “question/answer” interaction from the first article, the chat functionality requires storing the entire chat history and passing it with each request. Langchain provides various conversational memory classes for this purpose, and in this case, we can use the ConversationBufferMemory. Each session is assigned a memory object like this:
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True, output_key='answer')
For the actual Q&A, a different Chain is used:
qa = ConversationalRetrievalChain.from_llm(llm, instance.as_retriever(), memory=memory, get_chat_history=lambda h : h, condense_question_prompt=CONDENSE_QUESTION_PROMPT, combine_docs_chain_kwargs={"prompt": QA_PROMPT}, return_source_documents=True)
This may look complex, but Langchain simplifies the process. I had to figure out the correct way to call this method, as it seems that only a few people have experimented with it so far. The parameters we pass include the large language model (in this case, ChatOpenAI using the gpt-3.5-turbo model), the Chroma vector database instance, the conversational memory instance, a function to retrieve the chat history from that memory, and two prompts. Yes, two prompts.
The QA_PROMPT is the same as in the first article, setting the tone and purpose for the bot. The new prompt, CONDENSE_QUESTION_PROMPT, is used to condense the chat history and the next question asked into a standalone question. It is necessary to rerun this condensed question through the same process, as the required sources may change depending on the question. The prompt looks like this:
# Condense Prompt
condense_template = """Given the following conversation and a follow-up question, rephrase the follow-up question to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(condense_template)
With all of this in place, we simply need to call the qa object from the main web API and return both the response and the sources to the client:
query = request.args.get('query')
# Process the input string through the Q&A chain
query_response = qa({"question": query})
metadata_list = [obj.metadata for obj in query_response["source_documents"]]
response = {
'answer' : query_response["answer"],
'sources' : metadata_list
}
On the client-side, a chat-like UI must be implemented, allowing users to add messages in an endless container, call the web API, retrieve answers, and nicely format the sources. Unfortunately, this is beyond the scope of this article, but you can find the implementation of this functionality on combit’s GitHub repository.
Wrap Up
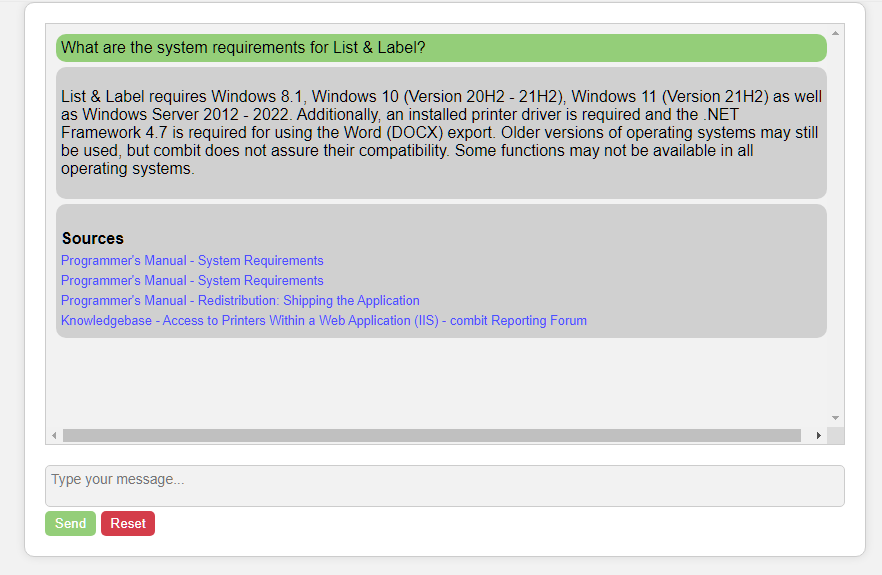
After investing several hours into this project, I have developed a prototype that showcases the potential of this technique. As you can see from the image below, the results are impressive:
Although I’m not a web designer, this prototype will replace the current bot combit is using. The new bot is faster, more versatile, and significantly more useful to the user.
Skrots: Taking It to the Next Level
At Skrots, we understand the importance of enhancing AI bots with chat and source retrieval capabilities. Just like the author of this article, we recognize the benefits of refining questions, resolving misunderstandings, and providing comprehensive sources to users. Our platform offers similar services, empowering businesses to create intelligent and interactive AI bots that deliver exceptional user experiences.
If you’re looking to extend your existing AI bot or build a new one, Skrots is the perfect partner for you. Visit us at https://skrots.com to learn more about our services and explore how we can assist you in achieving your goals.
Check out all the services we provide at https://skrots.com/services. Thank you!