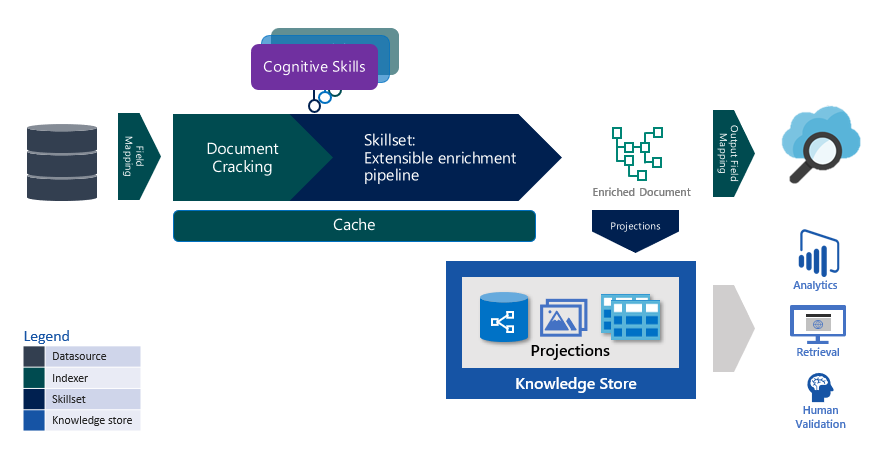
Incremental enrichment is a brand new characteristic of Azure Cognitive Search that brings a declarative method to indexing your knowledge. When incremental enrichment is turned on, doc enrichment is carried out at least value, whilst your expertise proceed to evolve. Indexers in Azure Cognitive Search add paperwork to your search index from a knowledge supply. Indexers observe updates to the paperwork in your knowledge sources and replace the index with the brand new or up to date paperwork from the info supply.
Incremental enrichment is a brand new characteristic that extends change monitoring from doc adjustments within the knowledge supply to all elements of the enrichment pipeline. With incremental enrichment, the indexer will drive your paperwork to eventual consistency along with your knowledge supply, the present model of your skillset, and the indexer.
Indexers have just a few key traits:
- Knowledge supply particular.
- State conscious.
- May be configured to drive eventual consistency between your knowledge supply and index.
Previously, enhancing your skillset by including, deleting, or updating expertise left you with a sub-optimal selection. Both rerun all the talents on your complete corpus, primarily a reset in your indexer, or tolerate model drift the place paperwork in your index are enriched with totally different variations of your skillset.
With the newest replace to the preview launch of the API, the indexer state administration is being expanded from solely the info supply and indexer area mappings to additionally embrace the skillset, output area mappings information retailer, and projections.
Incremental enrichment vastly improves the effectivity of your enrichment pipeline. It eliminates the selection of accepting the possibly giant value of re-enriching your complete corpus of paperwork when a talent is added or up to date, or coping with the model drift the place paperwork created/up to date with totally different variations of the skillset and are very totally different in form and/or high quality of enrichments.
Indexers now observe and reply to adjustments throughout your enrichment pipeline by figuring out which expertise have modified and selectively execute solely the up to date expertise and any downstream or dependent expertise when invoked. By configuring incremental enrichment, it is possible for you to to make sure that all paperwork in your index are all the time processed with probably the most present model of your enrichment pipeline, all whereas performing the least quantity of labor required. Incremental enrichment additionally provides you the granular controls to cope with situations the place you need full management over figuring out how a change is dealt with.

Indexer cache
Incremental indexing is made attainable with the addition of an indexer cache to the enrichment pipeline. The indexer caches the outcomes from every talent for each doc. When a knowledge supply must be re-indexed as a consequence of a skillset replace (new or up to date talent), every of the beforehand enriched paperwork is learn from the cache and solely the affected expertise, modified and downstream of the adjustments are re-run. The up to date outcomes are written to the cache, the doc is up to date within the index and optionally, the information retailer. Bodily, the cache is a storage account. All indexes inside a search service might share the identical storage account for the indexer cache. Every indexer is assigned a novel cache id that’s immutable.
Granular controls over indexing
Incremental enrichment gives a number of granular controls from guaranteeing the indexer is performing the best precedence activity first to overriding the change detection.
- Change detection override: Incremental enrichment provides you granular management over all elements of the enrichment pipeline. This lets you cope with conditions the place a change might need unintended penalties. For instance, enhancing a skillset and updating the URL for a customized talent will outcome within the indexer invalidating the cached outcomes for that talent. If you’re solely shifting the endpoint to a unique digital machine (VM) or redeploying your talent with a brand new entry key, you actually don’t need any current paperwork reprocessed.
To make sure that that the indexer solely performs enrichments you explicitly require, updates to the skillset can optionally set disableCacheReprocessingChangeDetection question string parameter to true. When set, this parameter will make sure that solely updates to the skillset are dedicated and the change will not be evaluated for results on the present corpus.
- Cache invalidation: The converse of that situation is one the place chances are you’ll deploy a brand new model of a customized talent, nothing inside the enrichment pipeline adjustments, however you want a selected talent invalidated and all affected paperwork re-processed to mirror the advantages of an up to date mannequin. In these situations, you’ll be able to name the invalidate expertise operation on the skillset. The reset expertise API accepts a POST request with the checklist of talent outputs within the cache that ought to be invalidated. For extra info on the reset expertise API, see the documentation.
Updates to current APIs
Introducing incremental enrichment will lead to an replace to some current APIs.
Indexers
Indexers will now expose a brand new property:
Cache
StorageAccountConnectionString: The connection string to the storage account that will probably be used to cache the intermediate outcomes.CacheId: The cacheId is the identifier of the container inside the annotationCache storage account that’s used because the cache for this indexer. This cache is exclusive to this indexer and if the indexer is deleted and recreated with the identical identify, the cacheid will probably be regenerated. The cacheId can’t be set, it’s all the time generated by the service.EnableReprocessing: Set to true by default, when set to false, paperwork will proceed to be written to the cache, however no current paperwork will probably be reprocessed primarily based on the cache knowledge.
Indexers may also help a brand new querystring parameter:
ignoreResetRequirement set to true permits the decide to undergo, with out triggering a reset situation.
Skillsets
Skillsets won’t help any new operations, however will help new querystring parameter:
disableCacheReprocessingChangeDetection set to true while you need no updates to on current paperwork primarily based on the present motion.
Datasources
Datasources won’t help any new operations, however will help new querystring parameter:
ignoreResetRequirement set to true permits the decide to undergo with out triggering a reset situation.
Finest practices
The really helpful method to utilizing incremental enrichment is to configure the cache property on a brand new indexer or reset an current indexer and set the cache property. Use the ignoreResetRequirement sparingly because it may result in unintended inconsistency in your knowledge that won’t be detected simply.
Takeaways
Incremental enrichment is a strong characteristic that permits you to declaratively make sure that your knowledge from the datasource is all the time per the info in your search index or information retailer. As your expertise, skillsets, or enrichments evolve the enrichment pipeline will make sure the least attainable work is carried out to drive your paperwork to eventual consistency.
Subsequent steps
Get began with incremental enrichment by including a cache to an current indexer or add the cache when defining a brand new indexer.