Foundational Models for Machine Learning: What You Need to Know
Artificial intelligence (AI) tools like ChatGPT and MidJourney have gained immense popularity in recent months. These AI tools have attracted millions of users and sparked a renewed interest in the field of AI. One of the exciting breakthroughs in this field is the concept of foundational models. These large-scale pre-trained models serve as a foundation for various machine learning applications, making it easier and more efficient to apply machine learning techniques to solve problems.
In this article, we will explore what foundational models are, how they work, and the opportunities and risks associated with them. We will also mention the Center for Research on Foundation Models at Stanford University and its contribution to the field. Let’s dive into the world of foundational models and discover how they can assist in solving problems efficiently, especially in light of the rise of AI tools like ChatGPT and MidJourney.
What are Foundational Models?
Foundational models are large-scale pre-trained models that can be fine-tuned for specific tasks. They are trained on massive amounts of data and have the ability to generalize to various tasks. Essentially, foundational models provide a base for many different machine learning applications, serving as a starting point for building more specialized models.
One of the significant advantages of foundational models is their ability to reduce the amount of training data required for specific tasks. Fine-tuning a pre-trained model often requires much less data compared to training a model from scratch. This simplifies the application of machine learning to new problems and reduces the time and costs associated with training models.

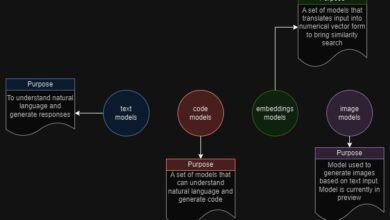
Some examples of foundational models include OpenAI’s GPT-3 and Google’s BERT. These models have been pre-trained on extensive amounts of text data and have shown impressive results in natural language processing tasks such as question-answering and language generation. GPT-3, for instance, can generate articles, essays, and code snippets that are incredibly similar to human-written ones.
Pre-training a foundational model involves training it on large amounts of data, which can take several days or even weeks, depending on the model’s size and the data used. Once pre-trained, the model can be fine-tuned for specific tasks by providing it with relevant data. Fine-tuning takes significantly less time than pre-training, making it a highly efficient way to apply machine learning to new problems.
In the next section, we will delve into the opportunities that foundational models present.
Opportunities of Foundational Models
Foundational models offer numerous opportunities that can greatly enhance the efficiency of machine learning applications. Here are some of the key opportunities:
Reduction in the amount of training data needed
One of the most significant advantages of foundational models is their ability to minimize the amount of training data required for specific tasks. These models have already been pre-trained on vast amounts of data, allowing them to learn from general patterns in the data. When fine-tuned for a specific task, they only need a relatively small amount of data related to that task. This reduction in training data leads to substantial time and cost savings.
To illustrate this reduction, let’s consider an example. Suppose you want to train a model to identify objects in images. If you were to train this model from scratch, you would need a large dataset of labeled images depicting different objects. This process is time-consuming and necessitates the collection and labeling of a significant amount of data.
However, by utilizing a foundational model that has already been pre-trained on a vast amount of image data, you can fine-tune it for the specific task of object identification with relatively little labeled data. The foundational model has already learned general patterns in the data, such as edges and shapes, which are crucial in identifying objects. By fine-tuning the pre-trained model, you can leverage this knowledge to quickly train a specialized model for your task.
This reduction in the amount of training data needed is particularly beneficial for machine learning applications that have limited amounts of labeled data. For instance, in medical imaging, there might be only a small amount of labeled data available for rare conditions. By using a pre-trained foundational model, one can reduce the amount of labeled data necessary to train a model for these conditions, making it easier to apply machine learning in these specialized areas.
If you visit our website, Skrots, you will find similar services that provide pre-trained models that can be customized to your specific needs. Feel free to check them out at https://skrots.com/services.
Generalization across tasks
Another advantage of foundational models is their ability to generalize across tasks. These models have been pre-trained on diverse data, enabling them to learn common patterns and features that can be applied to different tasks. Consequently, a single foundational model can be fine-tuned for multiple applications, eliminating the need for training a separate model for each task.
GPT-3, the powerhouse behind ChatGPT, is one of the most powerful foundational models available today. It has been pre-trained on an extensive amount of text data from various sources. This pre-training allows it to learn patterns and features applicable to a wide range of natural language processing (NLP) tasks. For instance, GPT-3 can generate human-like text for numerous applications, including article writing, summarization, and even poetry.
What makes GPT-3 even more remarkable is its ability to generalize to tasks it has not been explicitly trained on. It can be fine-tuned to perform tasks like question-answering and language translation, despite not being specifically trained for these tasks. This generalization stems from the foundational model’s learning of patterns and features common to many different NLP tasks, enabling it to apply this knowledge to new tasks with minimal fine-tuning.
This generalization across tasks is immensely valuable for machine learning applications, as it optimizes the utilization of resources and reduces the time and costs associated with training specialized models for each task. It also allows researchers to explore innovative ways of using foundational models to address problems across various domains.
Time and cost savings
Time and cost savings are significant advantages offered by foundational models, greatly benefiting businesses. Training a machine learning model from scratch can be time-consuming and expensive, involving the collection and labeling of substantial amounts of data, the setup of computing infrastructure, and the employment of specialized expertise.
By utilizing a pre-trained foundational model as a starting point, businesses can save significant time and money in their machine learning projects. For instance, suppose a business aims to build a machine-learning model capable of detecting fraudulent transactions in its payment processing system. By using a pre-trained foundational model trained on millions of transactions across various domains, the business can reduce the amount of labeled data needed to fine-tune the model for their specific use case. This, in turn, saves the business a considerable amount of time and money that would have been spent on collecting and labeling the same amount of data from scratch.
Additonally, since pre-training a model is a one-time process, the subsequent fine-tuning for specific tasks can be done much more quickly and efficiently than training a model from scratch. This allows businesses to iterate more rapidly on their machine learning projects and respond swiftly to changes in their business needs.
In summary, the time and cost savings offered by foundational models enable businesses to achieve their machine-learning goals more efficiently and cost-effectively.
Risks and Challenges of Foundational Models
While foundational models present significant opportunities for machine learning applications, they also bring along certain risks and challenges that need to be acknowledged and addressed. Here are some of the key risks and challenges:
Bias in the data used to train models
One of the main risks associated with foundational models is the potential bias in the data used to train them. Since these models are trained on large amounts of data, any biases present in the data can be magnified in the model’s output. This can lead to unfair and discriminatory outcomes in machine learning applications.
For example, if a pre-trained model is trained on data that exhibits bias against certain groups of people, such as minorities or women, the model may inadvertently reproduce these biases in its output. This can have significant implications in areas such as hiring or lending decisions, in which decisions based on biased data can perpetuate discrimination.
Malicious use of foundational models
Another risk associated with foundational models is the potential for malicious use. These models can be employed to generate deceptive text, images, or videos that are difficult to distinguish from real ones. This raises concerns in domains like cybersecurity and disinformation campaigns.
For instance, a malicious actor could utilize a pre-trained language model to create fake news articles or emails that appear to be written by reputable sources. Similarly, a pre-trained image generation model could be used to produce fake images that are indistinguishable from genuine ones, making it arduous to identify deepfakes.
Addressing the risks and challenges
Addressing the risks and challenges associated with foundational models necessitates a multi-faceted approach. It involves careful consideration of the data used to train these models, as well as the implementation of suitable safeguards to prevent their malicious use.
One approach to mitigating bias in foundational models is to meticulously curate the training data, ensuring its representation of real-world populations and situations relevant to the models’ applications. Techniques like adversarial training can also be employed to alleviate the effects of bias in machine learning models.
To address the risk of malicious use, appropriate safeguards such as user authentication, access controls, and monitoring should be implemented to prevent unauthorized access to pre-trained models. Moreover, raising public awareness about the risks associated with deepfakes and malicious use of AI is crucial in preventing their misuse proactively.
If you have used MidJourney, you may have come across prompts where the engine blocked content because it was deemed NSFW (not safe for work) or potentially violating their usage policies. This is an example of safeguards implemented by the AI engine.
In the final section, we will provide recommendations for businesses and organizations seeking to incorporate foundational models into their machine-learning applications.
Center for Research on Foundation Models
The Center for Research on Foundation Models is a research organization dedicated to advancing the field of foundational models and their applications in machine learning. Let’s take a look at the center, its goals, and its contributions to the field:
Overview of the Center for Research on Foundation Models
The Center for Research on Foundation Models is a collaborative effort involving leading universities and industry partners such as Stanford University, UC Berkeley, MIT, IBM, and Microsoft. The center focuses on developing foundational models that can be used as a launchpad for various machine learning applications, ranging from natural language processing to computer vision.
Goals of the Center
The main goal of the Center for Research on Foundation Models is to create foundational models that are more efficient, robust, and reliable than current models. They aim to build models that can learn from diverse data sources, generalize to different tasks, and minimize the need for extensive amounts of labeled data. Furthermore, the center is committed to addressing the ethical and societal implications of foundational models, especially the risks associated with bias and malicious use.
Contributions of the Center to the Field
The Center for Research on Foundation Models has made significant contributions to the realm of machine learning and artificial intelligence. The center has developed several foundational models that have established new performance benchmarks in diverse tasks, such as language modeling, question answering, and computer vision. Additionally, the center has contributed to the development of techniques for mitigating bias in machine learning models and preventing their malicious use.
The center’s work has garnered recognition from the research community, with researchers affiliated with the center receiving numerous awards and accolades for their contributions to the field of machine learning. The center’s endeavors are expected to have a profound impact on the future of machine learning and its applications across multiple domains.
In the final section, we will provide some important takeaways for businesses and organizations looking to incorporate foundational models into their machine-learning applications.
Conclusion
Foundational models are potent tools for machine learning applications, enabling businesses and organizations to streamline the process of training models. They offer substantial advantages, such as generalization across tasks, reduction in the need for labeled data, and significant time and cost savings.
However, foundational models also pose risks and challenges that must be addressed, including bias in the training data and the potential for malicious use. Mitigating these risks requires comprehensive approaches that consider the data used to train the models and implement suitable safeguards against misuse.
Looking ahead, the future of foundational models in machine learning appears promising. With ongoing research and development in this field, we can anticipate the emergence of even more efficient, robust, and reliable models that serve as powerful starting points for various applications. Furthermore, as foundational models become increasingly prevalent, it is essential to continue addressing the ethical and societal implications associated with them to ensure their responsible utilization for the benefit of society at large.
In conclusion, foundational models present significant opportunities for businesses and organizations seeking to implement machine learning solutions. However, it is crucial to address the risks and challenges associated with these models to ensure their safe and effective utilization in the future.
Frequently Asked Questions
Q: What is the difference between a foundational model and a regular machine learning model? A: Foundational models are pre-trained on extensive amounts of data, enabling them to learn general patterns and features. Regular machine learning models, on the other hand, are trained from scratch for specific tasks and require large amounts of labeled data to achieve high accuracy.
Q: Are there any ethical considerations when using foundational models? A: Yes, foundational models can be susceptible to bias and can perpetuate discriminatory outcomes if not properly curated and tested. Additionally, they can be used maliciously, such as in creating deepfakes.
Q: How do I know if a foundational model is suitable for my machine-learning application? A: It is essential to carefully consider the specific needs and requirements of your application, as well as the data available for training and fine-tuning the model. It may be helpful to consult with experts in the field or experiment with different models and techniques to find the best fit for your needs.
Q: What are some examples of foundational models? A: Examples of foundational models include GPT-3 for natural language processing, Vision Transformer for computer vision, and T5 for multi-task learning.
Q: How can I ensure that my fine-tuned model is not biased? A: One approach is to curate the training data carefully, ensuring that it is representative of real-world populations and situations relevant to the model’s application. Techniques like adversarial training can also be used to mitigate bias effects in machine learning models. It’s vital to thoroughly test the model to ensure it does not produce unfair or discriminatory outcomes.
If you want to explore more about foundational models and other services we provide, visit us at https://skrots.com. Additionally, you can check out our range of services at https://skrots.com/services. We offer similar services, providing pre-trained models that can be fine-tuned to meet your specific requirements. Thank you for reading!