Azure Synapse Analytics – Finest Practices To Load Information Into SQL Pool Information Warehouse
Within the earlier article, we discovered the method to load information to SQL Pool Information Warehouse in Azure Synapse Analytics. On this article, we’ll get into particulars of discovering one of the best ways to load information into SQL Warehouse with totally different optimizations for higher efficiency. We’ll study numerous facets to take into concern when loading the information. Varied practices are really useful and described intimately on this article with correct examples. Furthermore, we’ll question and carry out utilizing Azure Information Studio to entry the information warehouse we created in Azure.
This text is part of the Azure Synapse Analytics Articles Sequence. You possibly can take a look at different articles within the sequence from the next hyperlinks.
- Azure Synapse Analytics
- Azure Synapse Analytics – Create Devoted SQL Pool
- Azure Synapse Analytics – Creating Firewall at Server-level
- Azure Synapse Analytics – Join, Question and Delete Information Warehouse SQL Pool
- Azure Synapse Analytics – Load Dataset to Warehouse from Azure Blob Storage
- Azure Synapse Analytics – Finest Practices to Load Information into SQL Pool Information Warehouse
Information Preparation
Earlier than we even begin loading information from Azure Storage, probably the greatest issues we are able to do is information preparation. It’s important we all know the constraints of varied export information format such because the ORC File Format. As a way to cut back latency, to start with collocate the storage layer and the devoted SQL Pool. Subsequent, study the best way to work across the limitation of the file format. One of many most interesting methods to do this is to export subset of columns from information. We all know that the limitation for Polybase is 1 million bytes of knowledge i.e. we are able to’t load rows any greater than 1 million bytes. Thus, any textual content recordsdata in Azure Information Lake Retailer and Azure Blob Storage ought to have lesser than 1 million bytes of knowledge no matter desk schema. Subsequent, we are able to additionally break up it into small compressed recordsdata from massive compressed recordsdata to make it work.
Handle Acceptable Compute to run Load
Operating just one load at a time will present the quickest loading pace. Apart from, when it appears loading isn’t working at optimum pace be certain, minimal variety of masses are working concurrently. Moreover, while you require a big loading job, scaling up the devoted SQL pool in Azure can be a greater thought.
We will additionally create loading customers particularly devoted to working load. As a way to load the run with applicable compute assets, we are able to register because the loading person and run the load. This makes positive that the loading performs with the person’s useful resource class which is a far easy course of than alternating useful resource class of a person so as to match the necessity of the present useful resource.
Creating Loading Consumer
For this, we require the creation of loading person. Allow us to study to do it.
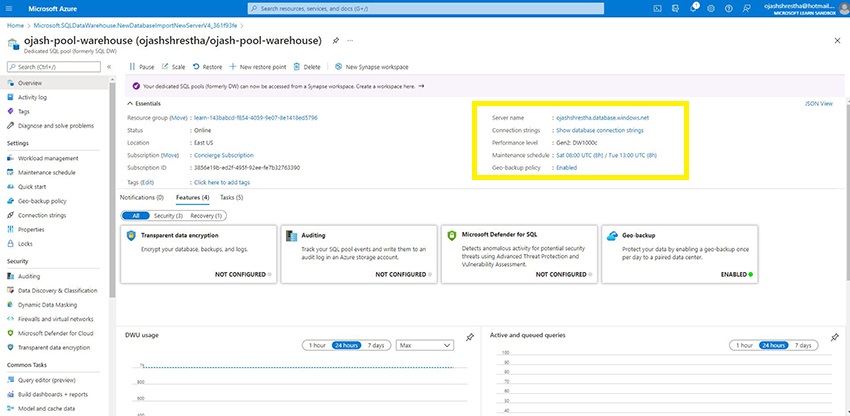
Step 1
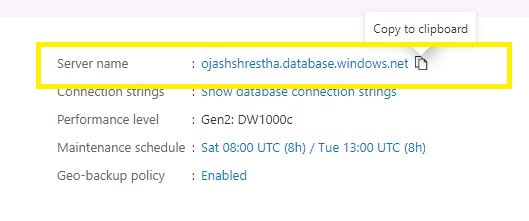
Go to the Azure Portal and duplicate within the Server title for the Devoted SQL Pool Information Warehouse.
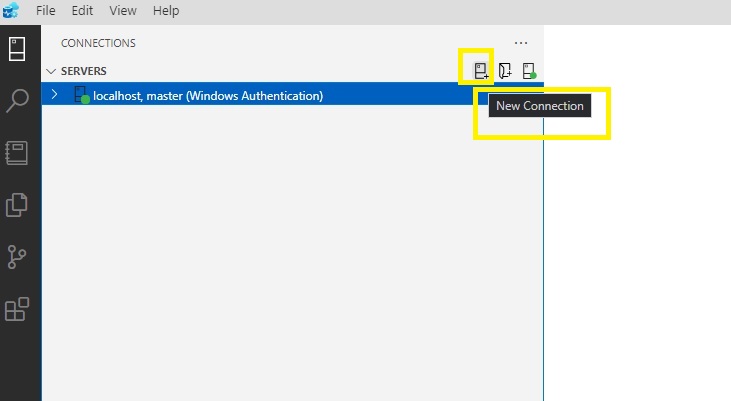
Step 2
Subsequent, in Azure Information Studio, Click on on New Connection.
Step 3
Now, we fill within the Connection Particulars.
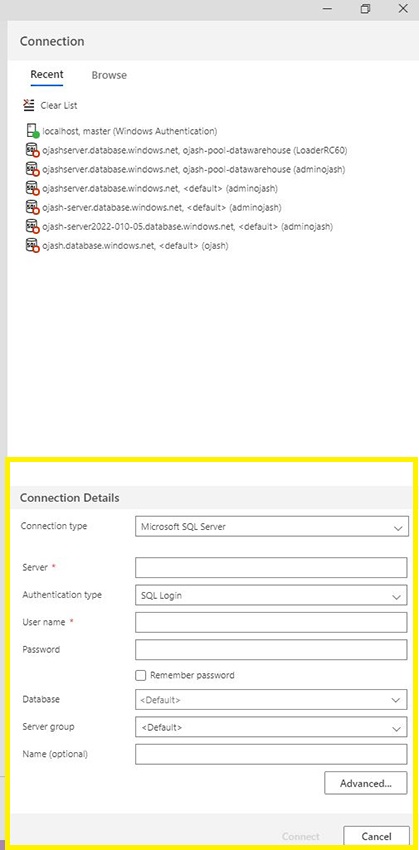
The Server title is the one which we copied earlier, the Authentication Sort should be SQL Login. Fill within the person title and password you arrange whereas creating the devoted SQL Pool in Azure. As soon as accomplished, click on on Join.
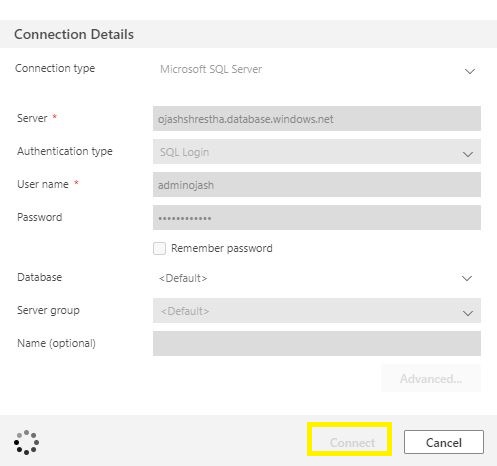
Step 4
Now, we are able to see the Devoted SQL Pool has been linked to Azure Information Studio as adminojash. We will additionally see the grasp and our principal information warehouse, ojash-pool-warehouse.
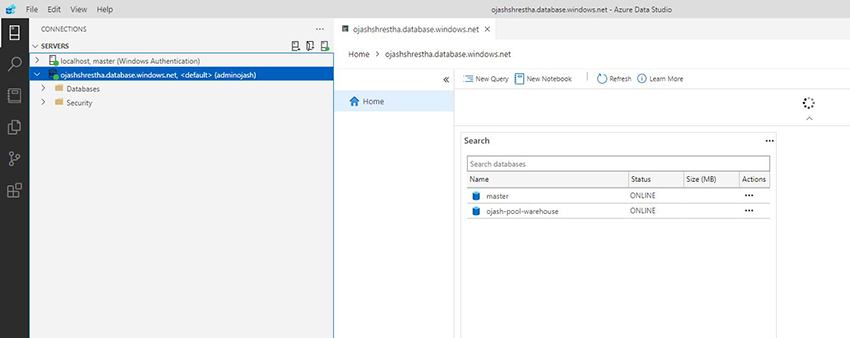
Step 5
Now, Proper Click on on SQL Pool and Click on on Create New Question. A brand new empty question web page will open.
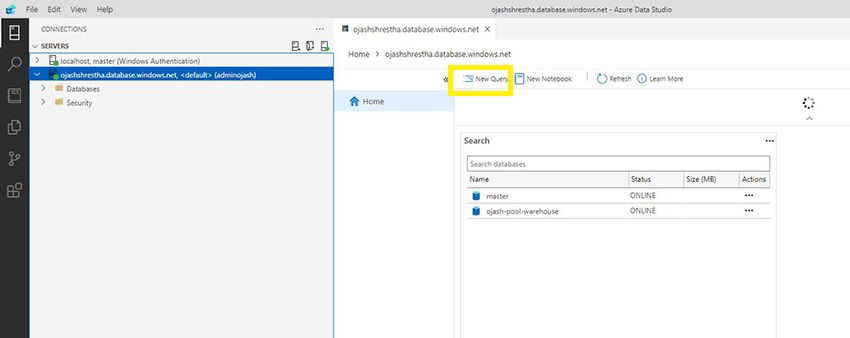
Step 6
Beneath the grasp, write the next question.
-- Hook up with grasp
CREATE LOGIN loader WITH PASSWORD = 'XnwQwe@21rpui()*&';
Step 7
Now, run the Question and the message will pop up because the command runs efficiently.
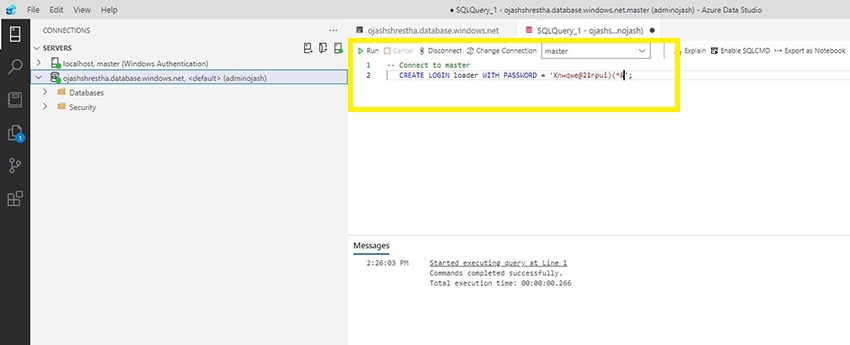
With this, the loading person named as loader has now been created.
Loading New Consumer
Step 8
Write within the following question to load within the warehouse with new person loader and hit run underneath your information warehouse title. Right here it’s, ojash-pool-warehouse.
-- Hook up with the devoted SQL pool
CREATE USER loader FOR LOGIN loader;
GRANT ADMINISTER DATABASE BULK OPERATIONS TO loader;
GRANT INSERT ON [dbo].[DimDate] TO loader;
GRANT SELECT ON [dbo].[ProspectiveBuyer] TO loader;
GRANT CREATE TABLE TO loader;
GRANT ALTER ON SCHEMA::dbo TO loader;
CREATE WORKLOAD GROUP DataLoads
WITH (
MIN_PERCENTAGE_RESOURCE = 0
,CAP_PERCENTAGE_RESOURCE = 100
,REQUEST_MIN_RESOURCE_GRANT_PERCENT = 100
);
CREATE WORKLOAD CLASSIFIER [wgcELTLogin]
WITH (
WORKLOAD_GROUP = 'DataLoads'
,MEMBERNAME = 'loader'
);
Step 9
Now, Proper Click on on SQL Pool and Click on on New Connection.
Step 10
Fill within the Connection Particulars. We’ll fill the small print as earlier for Connection Sort, Server, and Authentication Sort.
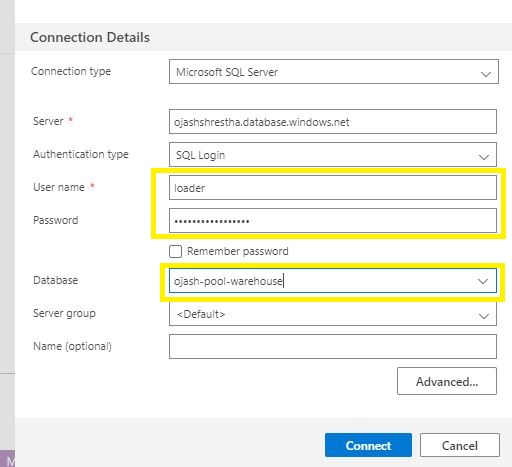
For person title and password, we fill within the title ‘loader’ that we set only in the near past with the password we arrange within the question. Be sure to write within the information warehouse title right here underneath database. Right here it’s ojash-pool-warehouse.
As soon as stuffed, Click on on Join.
Step 11
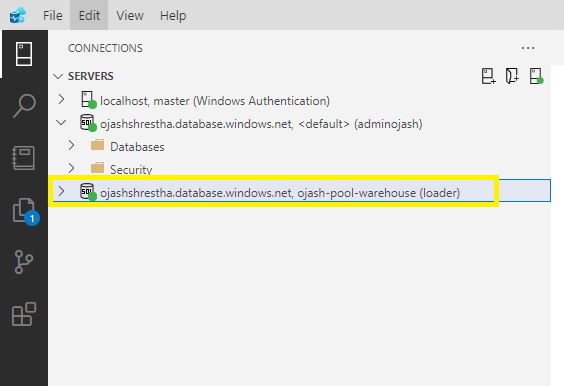
Now, we are able to see, the information warehouse has been linked with the person ‘loader’. Beforehand it was as adminojash.
Managing Entry Management for a number of customers
Very often we’ll arrange a number of customers to load information into the information warehouse. When querying to CREATE TABLE, it will require CONTROL Permission to the database and thus freely giving the entry of management of all schemas. This may not be a super method. It’s important to restrict these permissions utilizing the DENY CONTROL Assertion. We will carry out it with SQL Instructions as follows.
DENY CONTROL ON SCHEMA :: schema_A TO loader_B;
DENY CONTROL ON SCHEMA :: schema_B TO loader_A;
Staging Desk
Staging Desk is just a brief desk which accommodates the enterprise information and its major goal is to stage the incremental information from the transactional information. As a way to obtain the quickest attainable loading pace, load the information into staging desk whereas shifting information to information warehouse desk. For optimizing, we are able to outline the staging desk as a heap after which use the distribution choices as round-robin. It’s elementary to know it is a two-step course of the place we first load the information into the staging desk after which insert them into the manufacturing information warehouse desk. Outline staging desk as hash if the manufacturing desk makes use of hash distribution. As these steps are adopted, you’ll observe that a while would have been taken to load the staging desk however no information motion will incur in distribution whereas inserting to manufacturing desk making it fast.
Columnstore Index
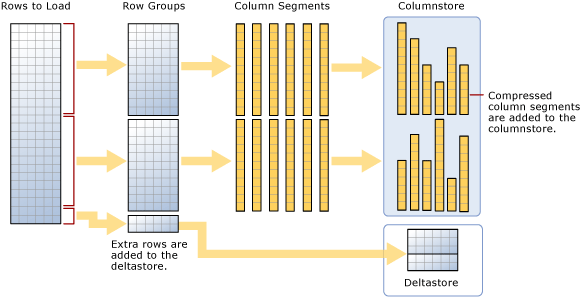
After we discuss the usual for querying and storing big information warehousing truth tables – columstore index is the one. This index will help us obtain over 10 occasions the question efficiency in comparison with conventional storage.
The columnstore index requires an enormous quantity of reminiscence so as to compress information into high-quality row teams and to carry out absolute best compression and attain index effectivity, the columnstore index would want to compress 1,048,576 rows into every of the rowgroup. This excessive demand would possibly now have the ability to be fulfilled throughout reminiscence strain effecting question efficiency. To ensure such situations don’t come up, we have to take some steps. We will guarantee this doesn’t happen by confirming loading person has sufficient reminiscence to carry out and obtain most compression charge through the use of the loading person which are the member of medium and huge useful resource class. Additionally, be certain to load sufficient rows to fill the brand new rowgroups fully which can mitigate the information going to deltastore.
Batch Measurement
Whereas utilizing SQLBulkCopy API and BCP, we must always at all times take into account a approach to attain higher throughput. This may be achieved by merely growing the Batch Measurement. It’s extremely really useful to make use of the batch dimension of round 100Ok to 1Million rows to optimum efficiency.
Statistics Creation
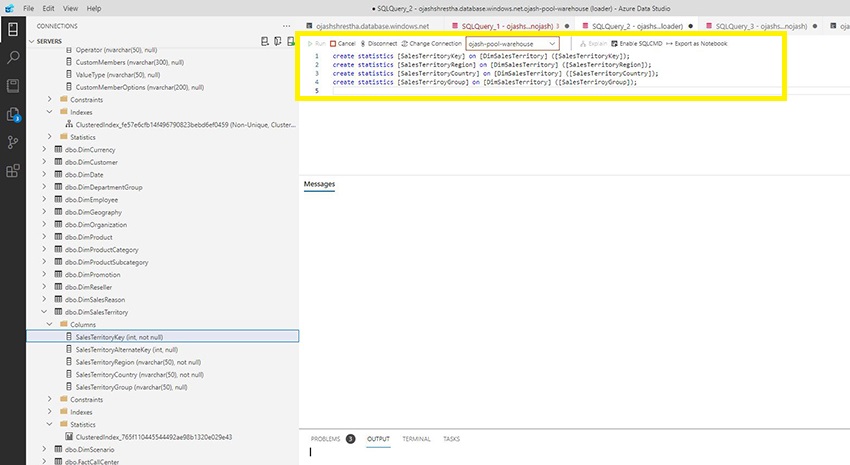
After the loading of knowledge is completed, it’s extremely really useful to create statistics to enhance the efficiency of question. We will carry out this manually or additionally allow the auto-creation of statistics. The next question will manually create the statistics for the 4 columns of DimSalesTerritory desk.
create statistics [SalesTerritoryKey] on [DimSalesTerritory] ([SalesTerritoryKey]);
create statistics [SalesTerritoryRegion] on [DimSalesTerritory] ([SalesTerritoryRegion]);
create statistics [SalesTerritoryCountry] on [DimSalesTerritory] ([SalesTerritoryCountry]);
create statistics [SalesTerritoryGroup] on [DimSalesTerritory] ([SalesTerritoryGroup]]);
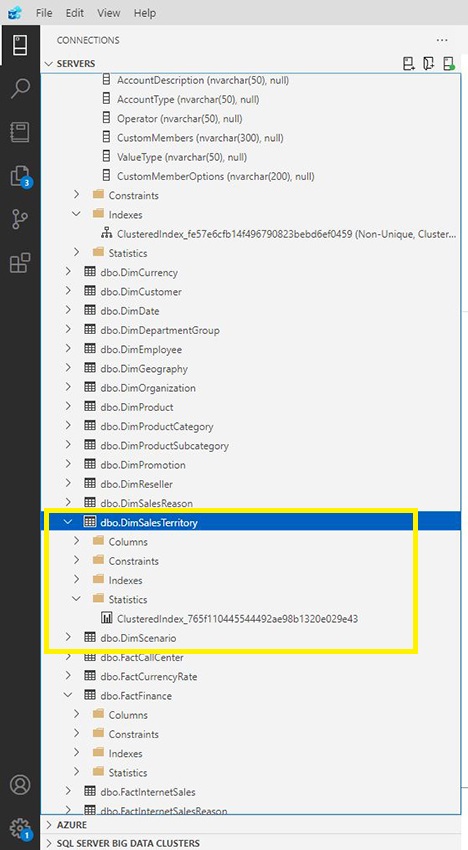
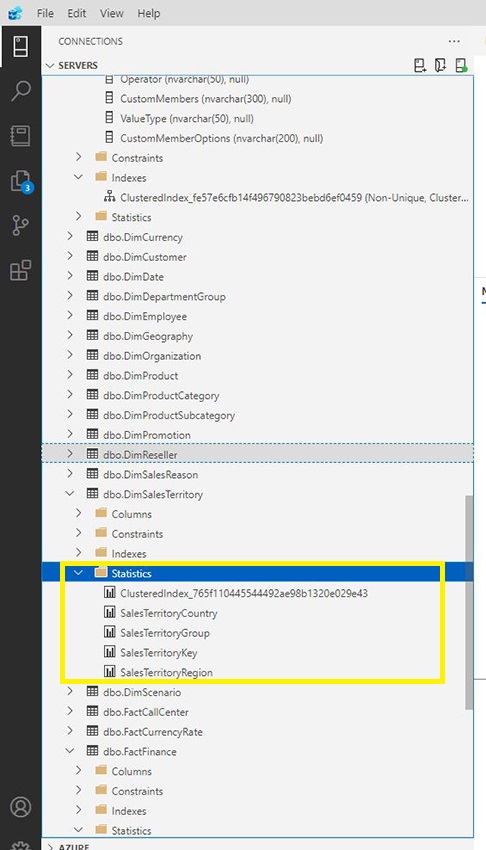
Right here we are able to see, on Azure Information Studio, there’s solely a clusteredindex underneath the DimSalesTerritory Desk.
As soon as the question is carried out, we are able to see the 4 new Statistics created. We will now see the brand new SalesTerritoryCountry, SalesTerritoryGroup, SalesTerritoryKey, and SalesTerritoryRegion statistics.
Conclusion
Thus, on this article, we discovered numerous practices to higher the efficiency whereas loading information to our datawarehouse desk. We discovered about Information Preparation, Managing Compute for Loading, Creating Loading Consumer, Connecting Datawarehouse with the brand new created person, Managing entry management and limiting the management for various customers, about staging desk and columnindex retailer. Furthermore, we additionally discovered about growing Batch Measurement for utilizing SQLBulkCopy API and discovered the necessity to created statistics for higher efficiency.