On this article, we’ll find out about Apache Spark and particularly deal with multitudes of choices of Apache Spark inside Azure. Apache Spark is the go-to identify for any big-data functions and it performs a significant position for initiatives which want to appreciate massive information and analytics.
Apache Spark
Supply: Microsoft
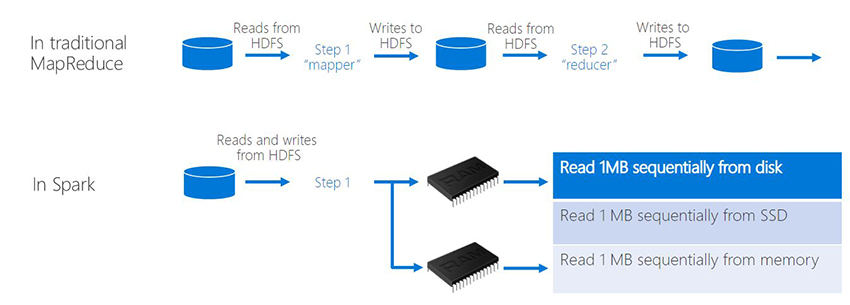
Developed on the AMPLab of College of California, Berkeley, Apache Spark is an analytics engine devoted to the processing of large-scale information. Fault Tolerance and Information Parallelism is supplied with programming cluster interface. The massive-data analytics utility efficiency may be boosted with Apache Spark with its parallel processing framework which helps in-memory processing.
In-Reminiscence cluster computing is supported by Apache with loading and caching of knowledge into reminiscence carried out with spark job which might then be queried thereafter. We all know that when in comparison with the disk-based functions like Hadoop that used Hadoop Distributed File System (HDFS), in-memory computing outshines with its quicker processing. Furthermore, distributed information units may be manipulated as native collections with the combination of Spark into Scala.
In Azure, there are quite a few choices of Apache Sparks. From Azure HDInsight, Azure Synapse Analytics, Azure Information Bricks, the Apache Spark has been applied for numerous use instances in Microsoft. Allow us to find out about every of them briefly.
Apache Spark in Azure HDInsight
Supply: Microsoft
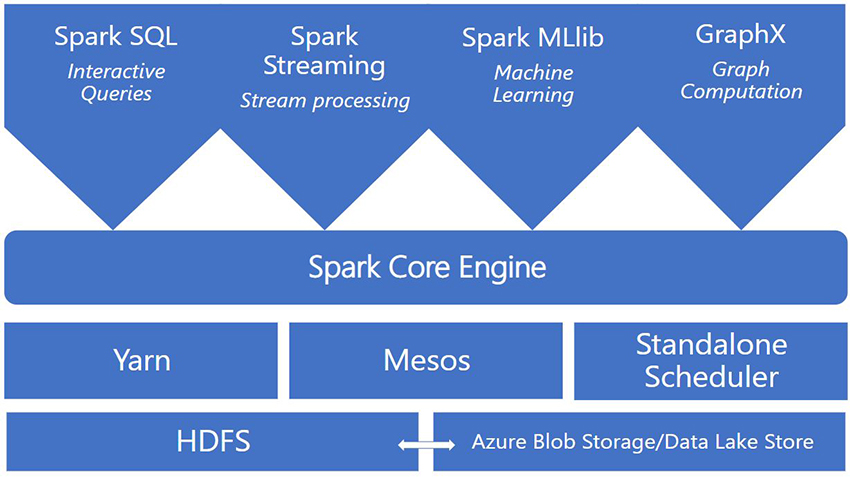
Azure HDInsight allows creating and configuring the Spark Clusters extraordinarily simply in Apache Spark. The complete Spark atmosphere is supplied thus making it handy to customise in Azure itself. Information may be saved and processed all inside Azure with Apache Spark in Azure HDInsight. Azure Information Lake Storage Gen 1 and Gen 2, Azure Blob Storage, all help Spark Clusters. Therefore, we are able to course of our Spark onto the pre-existing information shops.
Apache Spark in Azure Synapse Analytics
Supply: Microsoft
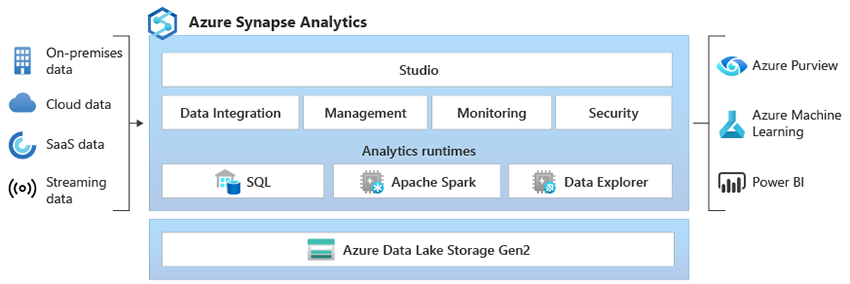
The Azure Synapse Analytics permits to create Spark Swimming pools which allows to load, mannequin, course of, and distribute information to provide analytic insights in Azure. Out of many, Apache Spark in Azure Synapse Analytics is likely one of the implementation of Apache Spark choices supplied by Microsoft in cloud. Creating and Configuring of Apache Spark Pool is extraordinarily straightforward. Moreover, the Spark Swimming pools can be utilized with Azure Storage and Azure Information Lake Technology 2 Storage. Much like Spark Clusters in Azure HDInsight, the Spark Pool in Apache Spark with Azure Synapse Analytics makes use of in-memory cluster computing which is quicker than conventional disk-based utility. Thus, there may be additionally no have to construction like within the conventional manner of map and scale back operations.
Advantages of Spark Clusters in Azure HDInsight and Spark Swimming pools in Azure Synapse Analytics
There are tons of advantages to utilizing Apache Spark Clusters in Azure HDInsight. The Spark Clusters in HDInsight may be setup in minutes via the Azure Portal, HDInsight, and Powershell. Furthermore, utilizing the Apache Zeppelin Notebooks and Jupyter Notebooks, the Spark Clusters are extraordinarily simpler to make use of too. With Apache Livy, jobs may be remotely submitted and monitored via the job server primarily based on REST API. Moreover, the Azure Information Lake Storage Gen 1 and Gen 2 are supported as each main and extra storage. Integration with Azure Providers and third-party IDEs will also be accomplished with the Azure Occasion Hubs, IntelliJ Thought, VSCode, and Eclipse respectively. Energy BI will also be built-in with Apache Spark in Azure HDInsight. Entry to over 200 libraries with Anaconda for information evaluation, visualization, and machine studying can be supplied. Lastly, Spark Clusters has 24/7 help and a powerful 99.9% SLA up-time.
Use Circumstances
Machine Studying
MLlib which is constructed on high of Spark can be utilized in Spark Pool throughout the Azure Synapse Analytics. Moreover, Anaconda which is mainly a Python Distribution with dozens of packages for information science and machine studying are additionally included. Mixed with the built-in helps for pocket book resembling Jupyter Pocket book and Zeppelin Notebooks, machine studying atmosphere has by no means been this straightforward to create earlier than. The identical MLlib will also be used from Spark Cluster throughout the Azure HDInsight.
Information Engineering
Information Engineering and Information Preparation are doable with Apache Spark in Azure Synapse Analytics. Quite a few languages are supported with a purpose to put together and course of large quantity of knowledge. With Azure Synapse Analytics, these information may be made extra helpful. For this, Spark SQL, PySpark, C#, and Scala are supported in Spark swimming pools with different libraries for connectivity and processing.
Enterprise Intelligence and Interactive Information Evaluation
Utilizing Apache Spark in HDInsight we are able to retailer our information inside Azure Information Lake Storage Gen1 and Gen2 in addition to Azure Blob Storage. We will analyze these information and construct stories from it. Extending to this, we are able to additionally combine Microsoft Energy BI to create interactive stories from these information. Different third-party instruments resembling Tableau will also be used with Spark Clusters in Azure HDInsight for Enterprise Intelligence instruments utilization.
Apache Spark utilizing Azure Databricks
The Apache Spark out there from Azure Databricks features a totally interactive workspace which makes collaboration between quite a few information sources and consumer straightforward as doable to provide breakthrough insights. From creating Spark jobs, loading and dealing with information, Azure Databricks allows all of it. Moreover, we are able to deal with our information work with swift Spark queries enabled by Databricks.
Distinction between Azure HDInsight VS Azure Synapse Analytics VS Azure Databricks
By now, we have come to appreciate that each Azure HDInsight, in addition to Azure Synapse Analytics, permits to run Apache Spark. However each of those choices of Azure are very totally different merchandise. The Azure HDInsight is majorly a cloud distribution of Hadoop parts and brings each Hadoop and Apache Spark collectively utilizing the identical instruments of Ambari and Apache Ranger to handle them. The configuration of HDInsight is a bit complicated as in comparison with Azure Synapse Analytics and is mainly at all times on. That is properly suited to instances the place one wants heavy compute and particular necessities. Furthermore, the training curve with Azure HDInsight is kind of steep too. Actually, loads of options of HDInsight are primarily based on Apache Spark. The Azure HDInsight has been round for fairly a while now and offers a spread of cluster kind to select from.
The Azure Synapse Analytics is furthermore a consumption-based service and opposite to always-on Azure HDInsight, the Azure Synapse Analytics may be paused. The Synapse is furthermore targeted towards bringing Large Information Analytics and Enterprise Information Warehousing collectively. From Serverless assets to integration with Enterprise Intelligence instruments and Machine Studying calls for, Azure Synapse Analytics fulfills it. Apart from, it’s also simpler to be taught Azure Synapse Analytics in comparison with Azure HDInsight. The key distinction in contrast with Azure HDInsight is that Azure Synapse Analytics incorporates quite a few Azure companies and is on the verge to change into a one-stop answer hub for Information Orchestration and Analytics. You may be taught extra about Azure Synapse Analytics from this Azure Synapse Analytics Article Sequence.
Azure Databricks on different hand is majorly an analytics platform primarily based on Apache Spark that’s optimized for the cloud platform of Microsoft – Azure. The premium Spark providing with Azure Databricks offers an business main efficiency for information scientists engaged on Spark workloads. If all we want is Spark Cluster, it’s endorsed to make use of Information Bricks over HDInsight because it offers higher efficiency. However, if in case you want heavy energy for logs of batch job, Azure HDInsight is the easiest way to go. Whereas we evaluate Azure Databricks to Azure Synapse Analytics, we are able to say that Databricks is a managed Apache Spark whereas Azure Synapse is extra so a managed SQL Information Warehouse.
Conclusion
Thus, on this article, we discovered about Apache Spark and the assorted companies in Azure which provides Apache Spark. We then dived into every of those companies and thus discovered concerning the Apache Spark providing in Azure HDInsight, Azure Synapse Analytics, and Azure Databricks. Furthermore, we additionally discovered about the advantages and makes use of instances of Apache Spark in Azure. Lastly, we mentioned the variations between Azure HDInsight, Azure Synapse Analytics, and Azure Databricks in peripheral with Apache Spark.