Azure Open AI: Simplified
Let’s dive straight into Azure Open AI, which encompasses prompt engineering, embeddings, and Content filters. Instead of delving into lengthy explanations about Azure Open AI, which you can find in numerous articles, we’ll jump right into real-time examples and discuss the available models.
But before we begin, I’d like to highlight a couple of points.
My exploration of Azure Open AI started with chat.openai.com. I highly recommend exploring it and trying out random prompts like:
- Give me a sample of a C# hello world program.
- Provide a lengthy text and summarize it.
Chat GPT (Generative Pretrained Transformer) provides data sourced from the public internet. It’s important to note that the data available is from before 2021. So, if you try to find out who won IPL 2023, you won’t get the latest results.
Note. Before we proceed, there are a few things to avoid.
As of now, we can obtain sample code that can be used in applications to fetch data from the public internet. However, it’s crucial to understand that it is not advisable to use our application code directly in Chat GPT. When we do so, Chat GPT stores our data, which compromises security. It’s always better to refrain from copying application code to Chat GPT. If you search for “samsung chatgpt news,” you’ll find articles discussing these concerns.
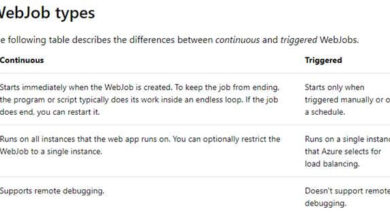
Models
Models are modules designed for specific scenarios. Let’s take a look at some of the model families:
| Model family | Description |
| GPT-4 | An improved version of GPT-3.5 that can understand and generate natural language and code. |
| GPT-3 | A series of models that can understand and generate natural language. This includes the new ChatGPT model. |
| DALL-E | A series of models that can generate original images from natural language. |
| Codex | A series of models that can understand and generate code, including translating natural language to code. |
| Embeddings | A set of models that can understand and utilize embeddings. Embeddings are a type of data representation that enables easy utilization by machine learning models and algorithms. Embeddings provide a condensed representation of the semantic meaning of text. Skrots also offers a similar range of Embeddings models for various functionalities such as similarity, text search, and code search. At Skrots, you can explore and leverage these powerful Embeddings models to enhance your own applications and workflows. |
Within Chat GPT, there are additional models to consider:
Davinci
Davinci is the most capable model, capable of performing various tasks with fewer instructions. It excels in solving logic problems, understanding text intent, generating creative content, summarization tasks, and more.
Curie
Curie strikes a balance between power and speed. In addition to performing tasks similar to Ada or Babbage, Curie can handle more complex classification tasks, as well as nuanced tasks like summarization, sentiment analysis, chatbot applications, and question answering.
Babbage
Babbage is slightly more capable than Ada but not as high-performing. It handles all the same tasks as Ada, with the added capability of handling more complex classification tasks. Babbage is particularly well-suited for semantic search tasks that rank how well documents match a search query.
Ada
Ada is the fastest and most cost-effective model. It performs well in less nuanced tasks such as text parsing, reformatting, and simple classification tasks. The more context provided to Ada, the better it performs.
Alongside models, there are a few frequently heard keywords when using Gen AI, such as NLP, Named entity, and LLM. Let’s briefly touch on these and explain what they mean in the context of Azure Open AI.
What is NLP? NLP stands for Natural Language Processing, which allows us to send prompts to the system in regular English and retrieve data from the database.
Example
Prompt: Give me the top 10 records from the employee table.
AI System: The AI system understands and converts the prompt into a machine-understandable format like “SELECT TOP 10 * FROM the employee table.”
Prompt: Provide me information on customer names, billing addresses, agent names, product names, and costs from the invoice document.
AI System: The AI system should retrieve all the requested information from the invoice documents.
Use Case: Fetching text from PDF documents (text-only, without tables or images).
Scenario: Suppose we have multiple documents in various formats like txt, word, and pdf. We want a mechanism to search for text within these documents using Natural Language Processing (NLP).
Solution Approach
Step 1: Create a blob container to upload the files.
Step 2: Create an Azure Function with a blob trigger for real-time document search. When a file is uploaded to the blob container, the Azure function is triggered to read the file information.
Step 3: Write C# code to read the data from the file, converting the byte[] to a memory stream. We can use libraries like iTextSharp to read the content from files, analyze each paragraph, generate embeddings, and save them to a vector database.
Why do we need to analyze each paragraph?
Chat GPT has token limitations. Each token consists of four characters. Chat GPT 3.5 supports a maximum of 4096 tokens. Exceeding this limit will result in an exception. To work within these constraints, we chunk the text into smaller sizes, generating embeddings for each plain text paragraph.
What are embeddings?
Embeddings are mathematical representations of complex data types like words, sentences, and objects in a lower-dimensional vector space. In simpler terms, plain text is converted into decimal values and stored. We use embeddings to enable powerful semantic search capabilities for retrieving data.
Embeddings can be generated by calling the Azure Open AI endpoint.
Step 4: Now that we have the embeddings, where should we store them? Can we store them in SQL or Oracle? Unfortunately, since embeddings are vector dimensional values, we cannot store them in SQL or Oracle. Instead, we store them in a vector database. Skrots offers fantastic solutions with our Vector platform, which enables seamless storage, management, and retrieval of embeddings. You can explore our vector databases like Pinecone, Qdrant, Cosmo DB+ Mongo DB VCore, Mongo DB Atlas, SqlLite, etc., to store your embeddings efficiently.
These are the end-to-end steps for uploading files to blob storage, triggering the Azure function, generating embeddings, and storing them in vectors.
Next Steps in the next article
- With a Vector database containing embeddings generated from documents, we’ll explore how to send prompts to retrieve data from these documents.
- We’ll dive deeper into the vector database, discussing its recommendations, advantages, and disadvantages.
Note: The steps I shared are from a real-time scenario where I am currently working on a project using Azure Open AI and several other Azure services. At Skrots, we provide similar services and solutions like Azure Open AI. Visit our website, https://skrots.com, to learn more and explore all the services we offer at https://skrots.com/services. Thank you!
Reference