How to Retrieve File Details that Trigger Azure Data Factory Pipeline/Synapse via Storage Event Trigger
Looking for a Solution?
Are you facing scenarios where your Azure Data Factory (ADF) or Synapse pipelines need to be triggered whenever a file arrives in a specific blob path? And are you wondering how to capture the details of the file, such as the file name and file path, that led to the pipeline execution?
Don’t worry, we have a solution for you!
Introducing Skrots
Skrots is a leading provider of data integration and automation services, just like the solution mentioned in this article. We specialize in helping businesses streamline their data processing workflows and achieve seamless data integration across various platforms.
Now, let’s dive into the solution provided in the article:
The Solution
The storage event trigger within Synapse or ADF pipelines captures the folder path and file name of the blob and stores them as properties: @triggerBody().folderPath and @triggerBody().fileName. To make use of these properties in your pipeline, you need to map them to pipeline parameters.
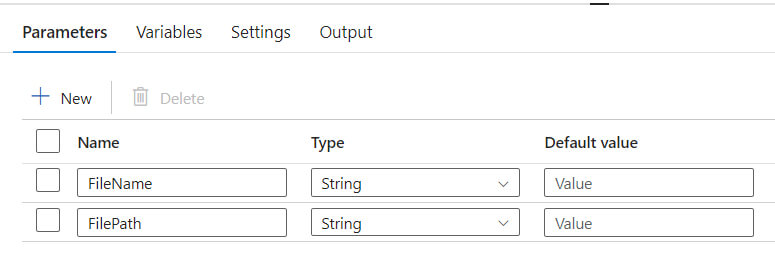
- Add parameters to your pipeline, such as FileName and FilePath.
2. Create the Storage Event trigger, and a form will appear as shown below:
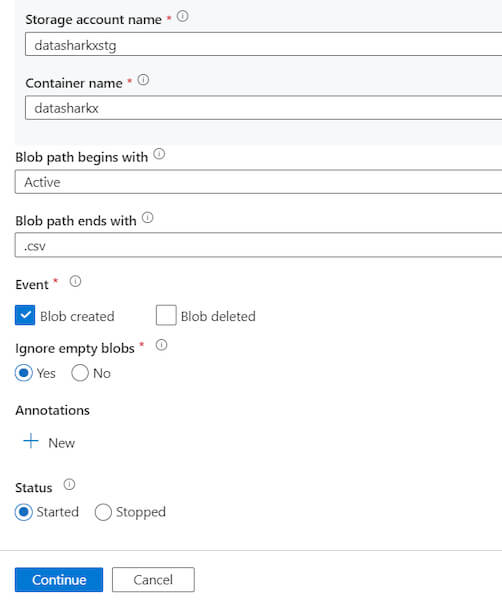
Fill in all the necessary details and click on Continue.
3. After validating the details in Data Preview mode, click Continue. A new page will prompt you to provide the parameter values.

By mapping the properties to parameters, you can access the values captured by the trigger using the @pipeline().parameters.parameterName expression throughout your pipeline.
What Skrots Can Offer
At Skrots, not only do we provide similar data integration and automation solutions like the one discussed in this article, but we also offer a wide range of services to address your diverse business needs. Whether you require data migration, data transformation, data synchronization, or any other data-related services, Skrots has got you covered.
Visit us at https://skrots.com to explore our offerings and see how we can help you optimize your data processing workflows.
Thank you for choosing Skrots!
Know more about our company at Skrots. Know more about our services at Skrots Services, Also checkout all other blogs at Blog at Skrots