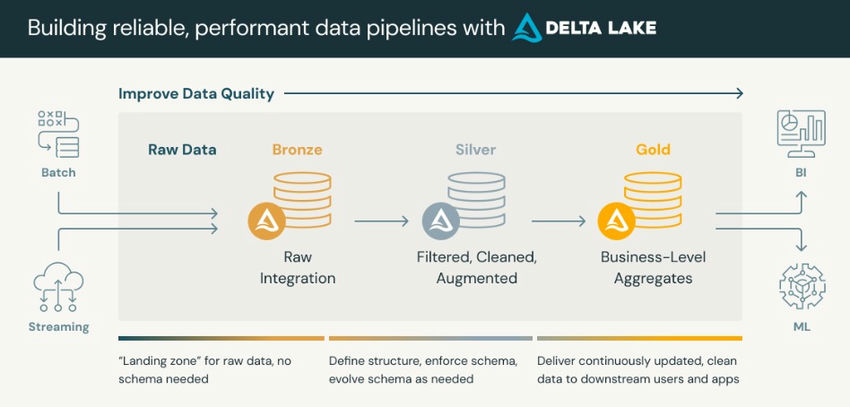
Medallion Structure Layers
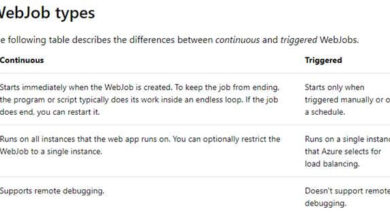
The Medallion Structure is structured into three layers, every taking part in a vital function within the information processing pipeline.
The Medallion Structure is a great information group method utilized in lakehouses. It goals to boost information construction and high quality regularly by passing it by means of layers: Bronze, Silver, and Gold tables. Generally referred to as ‘multi-hop’ architectures, they guarantee a clean circulation of information refinement and enrichment.
- Bronze Layer (Ingestion Layer): This layer is the entry level for information into the system. It includes ingesting uncooked information from numerous sources, equivalent to databases, information lakes, and streaming platforms.
- Silver Layer (Processing Layer): The silver layer is the place the uncooked information is remodeled, cleaned, and enriched to make it appropriate for evaluation. It includes processing duties like information transformation, normalization, and aggregation.
- Gold Layer (Storage Layer): The gold layer shops the refined and processed information in a structured format, making it readily accessible for analytics and visualization. It usually includes storing information in information lakes, information warehouses, or NoSQL databases.
Actual-Time Use Case E-commerce Gross sales Evaluation
Let’s contemplate an e-commerce platform that wishes to investigate its gross sales information in real-time to optimize advertising methods and stock administration. The Medallion Structure can effectively deal with this situation.
- Bronze Layer (Ingestion): Make the most of Databricks Autoloader to ingest JSON information from Azure Blob Storage Information Lake Gen2.
- Silver Layer (Processing): Implement information processing pipelines utilizing Apache Spark on Databricks to cleanse, rework, and analyze the incoming gross sales information.
- Gold Layer (Storage): Retailer the processed information in a structured format on Azure Blob Storage / Amazon S3 or Unity Catalog for simple accessibility and scalability.
- Analytics and Visualization: Visualize gross sales developments, buyer habits patterns, and stock insights utilizing instruments like Tableau or custom-built dashboards.
Exploring Databricks Autoloader Function
Databricks Autoloader is a characteristic that simplifies information ingestion from cloud storage into Delta Lake tables. It screens a specified listing for brand new information and routinely masses them into the Delta desk, making certain information freshness and reliability.
Instance
Suppose now we have a Delta desk named sales_data saved in Databricks Delta Lake, and we wish to repeatedly ingest new gross sales information information from Azure Blob Storage Delta Lake Gen2.
Processing Gross sales Information with Apache Spark on Databricks
# Configure Autoloader
spark.conf.set("spark.databricks.delta.autoloader.parallelism", "1000")
# Ingest new JSON information into Delta desk from Azure Blob Storage Information Lake Gen2
spark.readStream
.format("cloudFiles")
.choice("cloudFiles.format", "json")
.choice("cloudFiles.maxFilesPerTrigger", 1000)
.choice("cloudFiles.connectionString", "DefaultEndpointsProtocol=https;AccountName=<storage_account_name>;AccountKey=<storage_account_key>;EndpointSuffix=core.home windows.web")
.load("abfss://<container_name>@<storage_account_name>.dfs.core.home windows.web/<path>")
.writeStream
.format("delta")
.choice("checkpointLocation", "s3://path/to/checkpoint")
.begin("/mnt/information/sales_data")
Within the above instance
- We’re utilizing the cloud information format with Databricks Autoloader to ingest JSON information from Azure Blob Storage Information Lake Gen2.
- The connection string (cloudFiles.connectionString) is supplied to authenticate and entry the Azure Blob Storage.
- Regulate <storage_account_name>, <storage_account_key>, <container_name>, and <path> placeholders along with your precise Azure Blob Storage particulars.
- The processed information is written to a Delta desk in Azure Databricks.
This setup will repeatedly monitor the required Azure Blob Storage Information Lake Gen2 listing for brand new JSON information and routinely load them into the Delta desk in Azure Databricks for processing and transformation.
Know extra about our firm at Skrots. Know extra about our providers at Skrots Companies, Additionally checkout all different blogs at Weblog at Skrots