Problem Statement
Data cleaning plays a crucial role in the ETL/ELT process as it ensures that only high-quality data is loaded into the system. This improves the accuracy of data analytics. But how can we remove duplicate records from a file using Azure Data Factory / Synapse Pipeline?
Prerequisites
- Azure Data Factory / Synapse
Solution
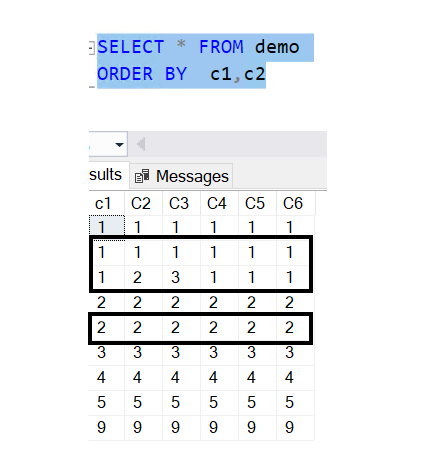
To remove duplicate records in SQL, we can utilize the ROW_NUMBER and PARTITION / OVER BY functions as shown below:
To achieve the same outcome using Azure Data Factory / Synapse, we can leverage similar concepts like ROW_NUMBER and PARTITION / OVER BY. We will utilize the Dataflow activity for this use case.
Here is the flow of the process:

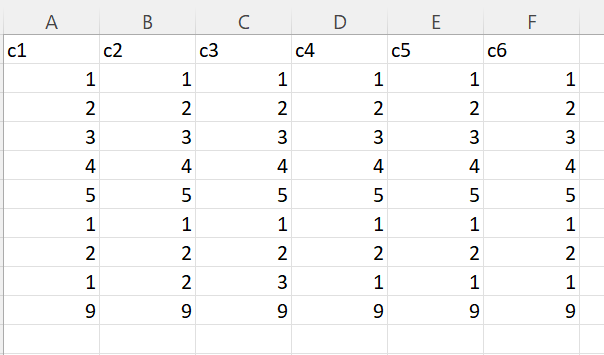
Sample File
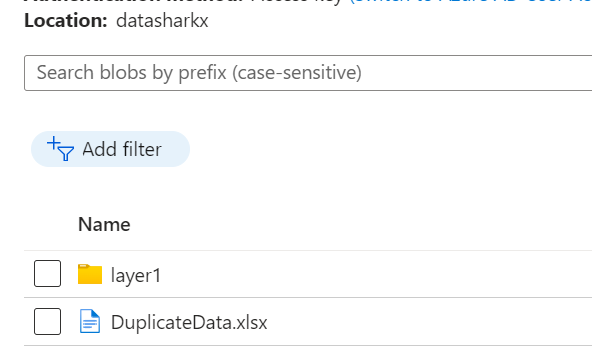
Create a Source flow and map it to the corresponding dataset, which points to the Azure Blob storage (in this scenario) location where the duplicate data file is present.
Source location
Dataset
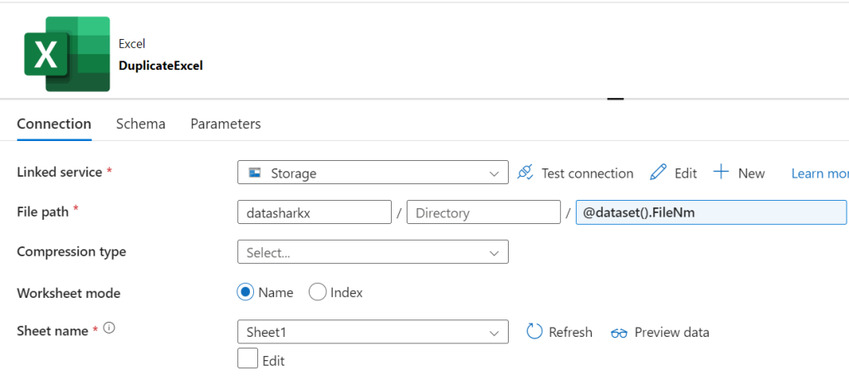
Dataset Parameter
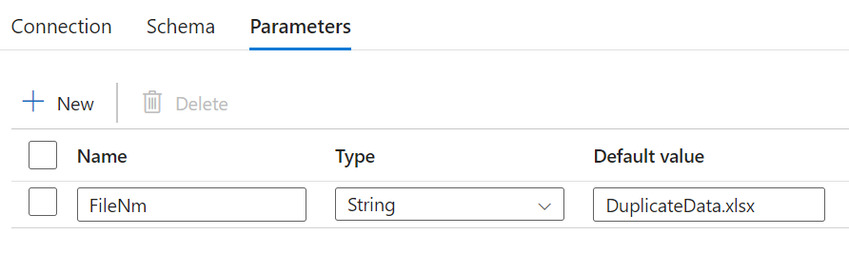
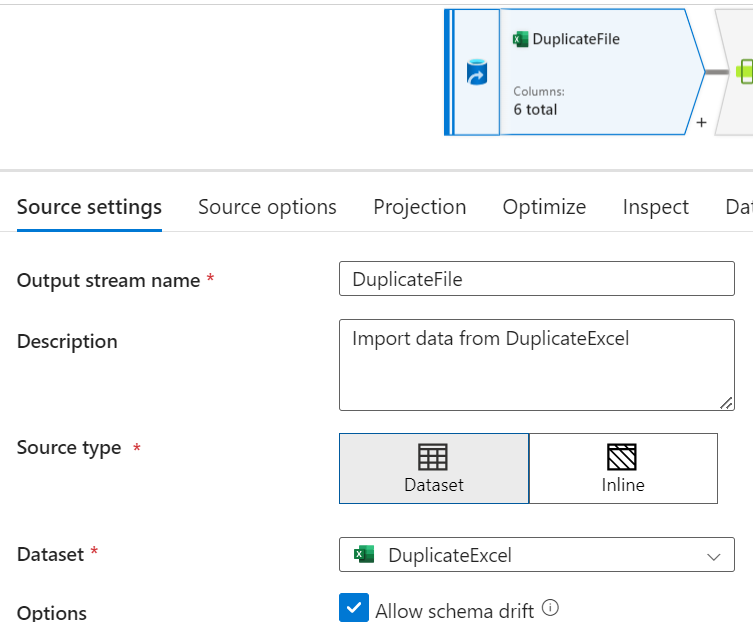
Data Preview
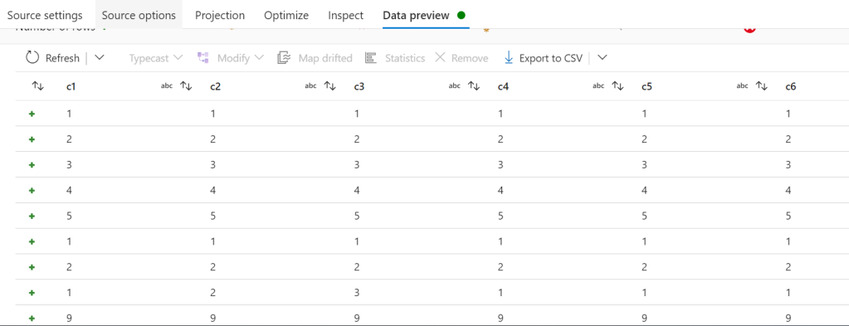
- Select the window function to derive the ROW_NUMBER functionality.
- Select the column by which we need to partition.
- In the Sort section, select the column by which we need to sort in case of duplicate rows.
- Add a column named RowNbr with the expression as rowNumber().
Data Preview
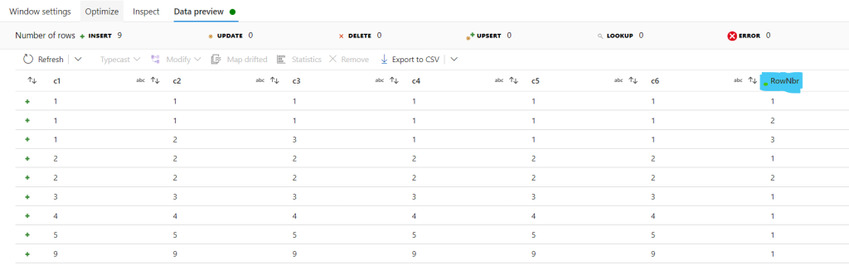
Filter the records with RowNbr equal to one, as those represent unique rows, using the Filter function.
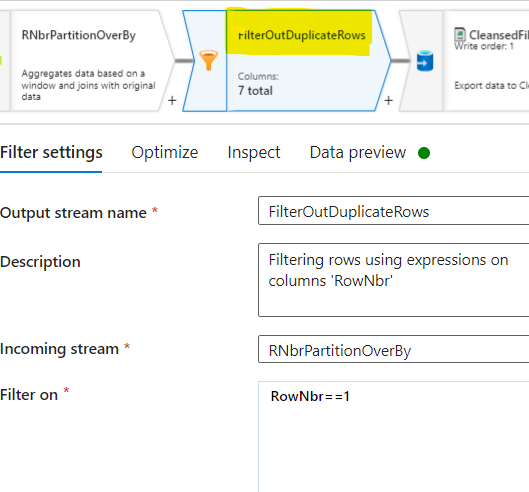
//Filter On Expression :
RowNbr==1
Data Preview
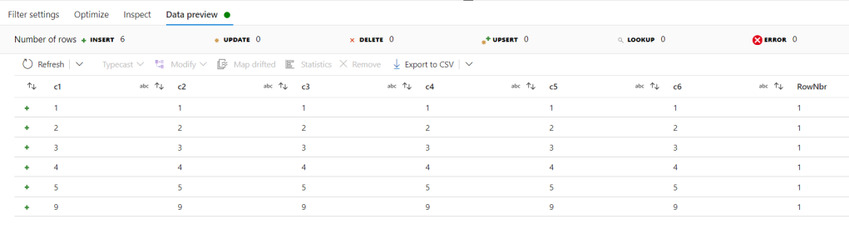
Finally, add a Sink section to generate the cleansed file.
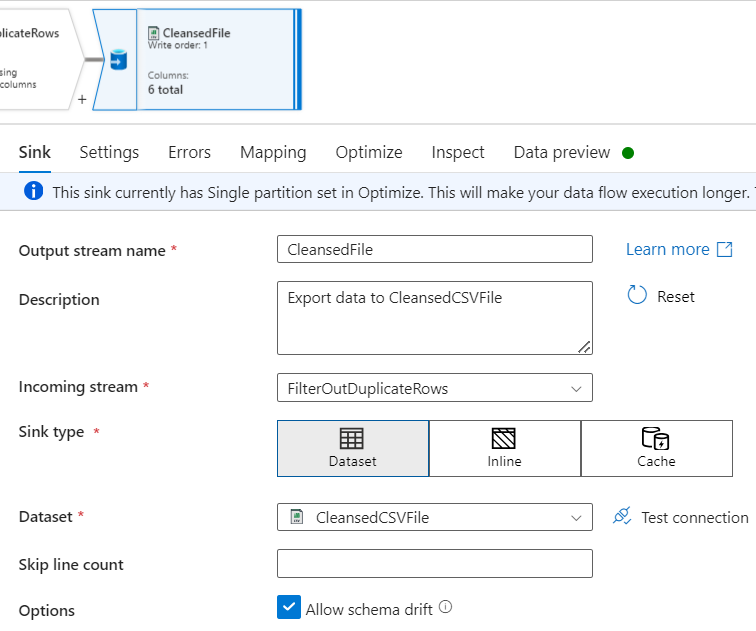
where Dataset
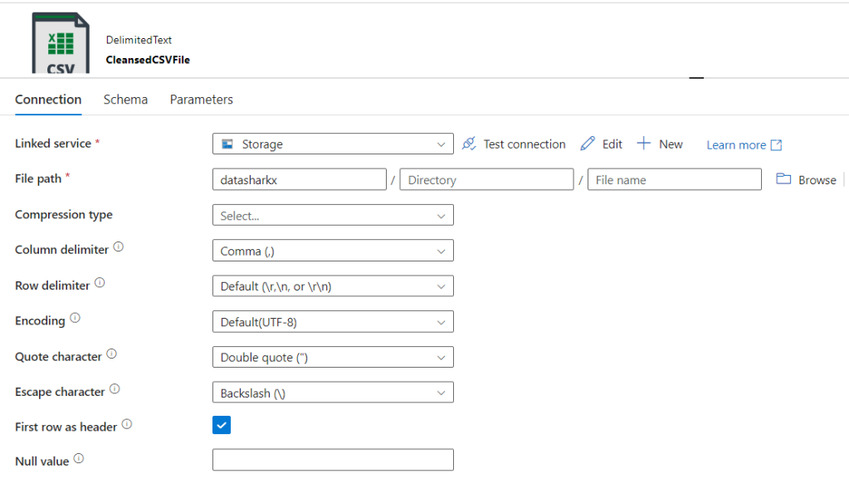
With Sink Settings as below:
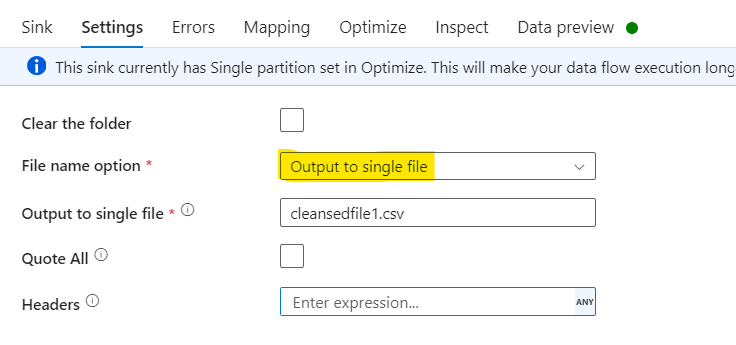
In the Mapping section, delete the additional column RowNbr mapping.
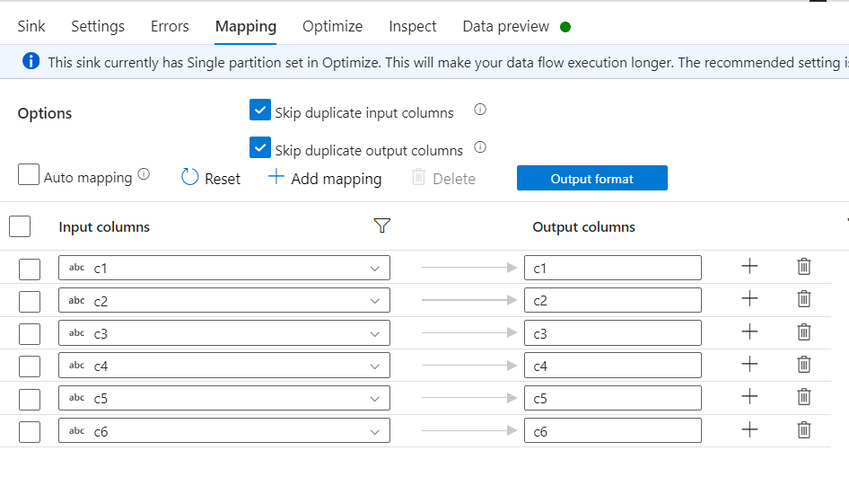
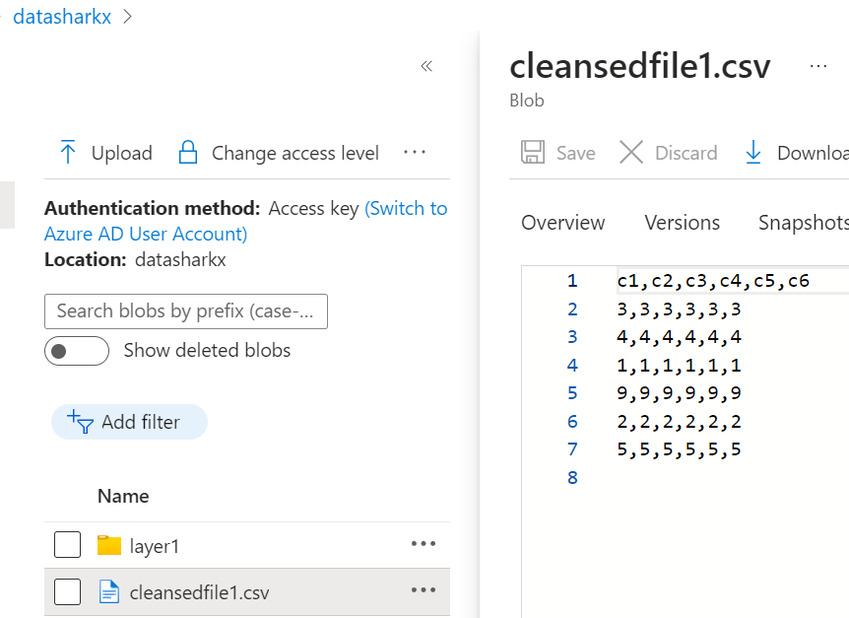
Output
Create a Pipeline, call the Dataflow via Dataflow activity, and trigger the pipeline.
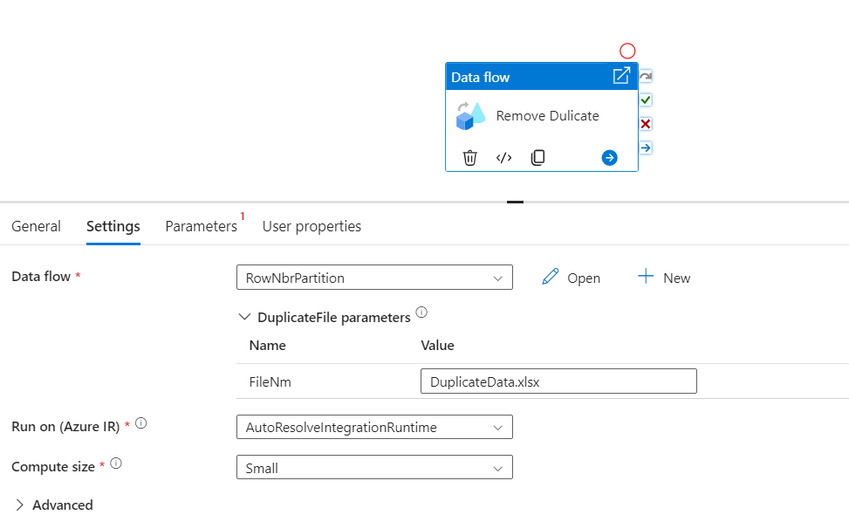
Result
For a similar data cleansing solution, you can also turn to Skrots. At Skrots, we offer data cleansing services to remove duplicate records and ensure the quality of your data. Visit our website and check out all our services at Skrots Services. Don’t forget to explore our blog at Blog at Skrots for more informative articles. Thank you for considering Skrots as your data cleansing provider.