This put up explains how one can successfully union two tables or information frames in databricks.
There are totally different strategies to deal with the union and this put up explains how one can leverage the native spark assertion to get the anticipated outcome.
Once we begin fascinated about union, we want to verify the column names on each tables are the identical so that we are going to get the anticipated outcome. What’s going to occur if the columns are totally different and in a unique order?
Allow us to see the easy outcome utilizing UNION in spark.sql.
I’ve a easy information body outlined for this demo.
df1 = spark.createDataFrame([[1, "John", "$25000"]], ["ID", "Name", "Sales"])
df2 = spark.createDataFrame([[2, "Bob", "Marketing"]], ["ID", "Name", "Department"])
Allow us to see the spark.sql with the union for the above 2 information frames.
I’m making a view out of the above 2 information frames to make use of the SQL syntax within the union assertion.
df1.createOrReplaceTempView("df1")
df2.createOrReplaceTempView("df2")
spark.sql("choose * from df1 union choose * from df2").present()
Verify the outcome beneath,
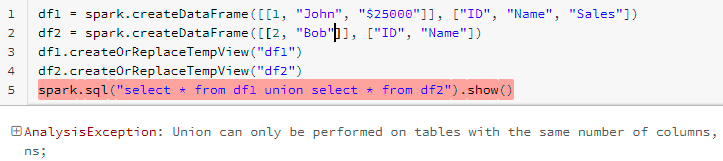
When you see the outcome, it’s merely doing the union of each datasets. As you already know, if we strive with a unique variety of columns then it’s going to by means of an error like beneath,
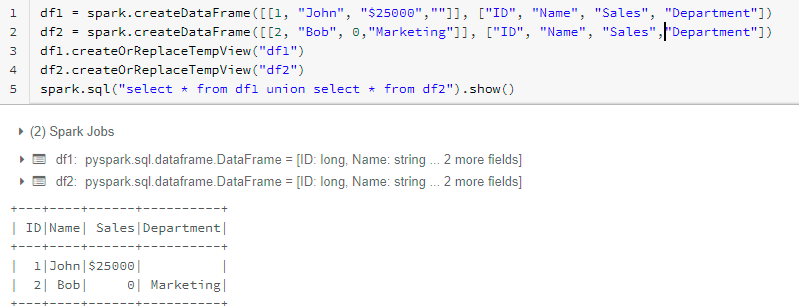
To realize the right outcome, we have to place the column incorrect order and add lacking columns with null values.
Allow us to come to the purpose, I’m going to point out how one can obtain the right outcome simply.
In spark, now we have a operate referred to as “unionByName”. It will assist to get the anticipated outcome.
Allow us to go together with the identical pattern and begin to use the unionByName operate. Right here, we don’t must create a view and play with SQL.

The above syntax failed as a result of it was on the lookout for the identical column names. Allow us to add a property referred to as “allowMissingColumns=True” and examine.
df1.unionByName(df2,allowMissingColumns=True).present()
The above syntax failed as a result of it was on the lookout for the identical column names. Allow us to add a property referred to as “allowMissingColumns=True” and examine.
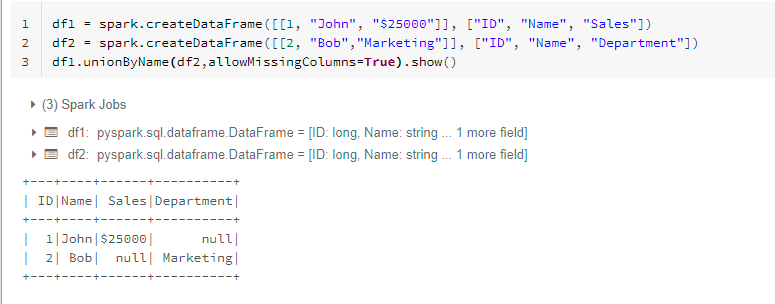
We obtained the anticipated lead to one step. The opposite magnificence is it’s going to present the right outcomes even the column title are in a unique order.
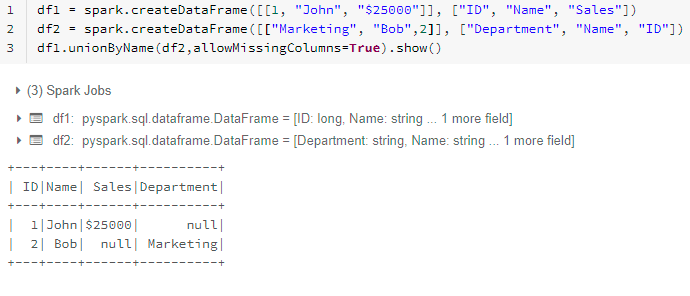
That is one thing just like UNION ALL when it comes to the outcome. You probably have matching values in each the dataset then it’s going to present each the values. When you want a definite of the outcome then use distinct() with the operate as like beneath,
df1.unionByName(df2,allowMissingColumns=True).distinct().present()
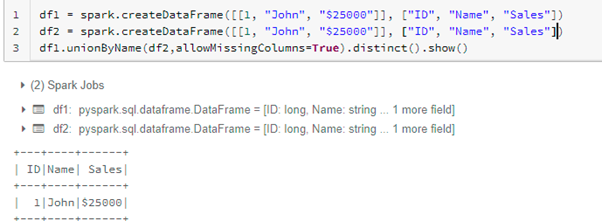
Let me know if you’re doing this another way within the remark beneath.
Completely satisfied Studying!!