The uncooked information, missing context and which means, by itself is just not a supply of actionable insights, irrespective of what number of petabytes of knowledge you might have collected and saved. This kind of unorganized information is commonly saved in quite a lot of storage techniques, together with relational and non-relational databases, however with out context, it’s not helpful for analysts or information scientists.
For giant information to be helpful, it requires companies that may orchestrate and operationalize processes, thus turning unorganized information into enterprise insights which can be actionable. Azure Knowledge Manufacturing facility was constructed to allow companies to remodel uncooked information into actionable enterprise insights. It does this by finishing up advanced hybrid extract-transform-load (ETL), extract-load-transform (ELT), and information integration tasks.
Think about a automobile rental firm that has collected petabytes of automobile rental logs which it holds in a cloud information retailer. The corporate want to use this information to realize insights into buyer demographics, preferences and utilization habits. With these insights, the corporate may extra successfully up-sell and cross-sell to its clients, in addition to enhance buyer expertise and develop new options, thus driving enterprise progress.
To be able to analyze the automobile rental logs held within the cloud information retailer, the corporate wants to incorporate contextual information comparable to buyer info, automobile info, and promoting and advertising and marketing info. Nonetheless, this contextual info is saved in an on-premises database. Subsequently, with the intention to make use of the automobile rental logs, the corporate should use the information within the on-premise database, combining it with the log information it has in a cloud information retailer.
To be able to extract insights from its information, the corporate would in all probability need to course of the joined information through the use of a Spark cluster within the cloud after which publish the remodeled information right into a cloud information warehouse, comparable to Azure SQL Knowledge Warehouse, so a report could be constructed simply on prime of it. This workflow will in all probability should be automated, in addition to being monitored and managed on a every day schedule.
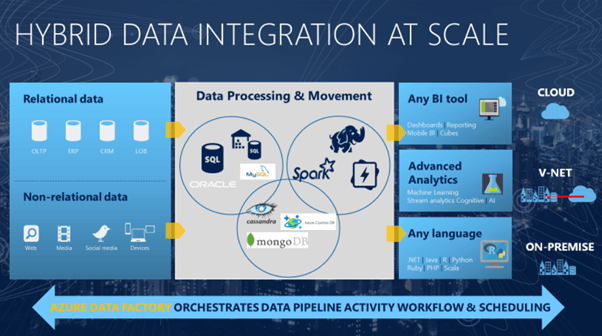
This isn’t an uncommon information situation for an organization in nowadays of huge information. Azure Knowledge Manufacturing facility has been designed to unravel simply such information situations. Azure Knowledge Manufacturing facility is a cloud-based information integration service that lets you create data-driven workflows within the cloud for orchestrating and automating information motion and information transformation.
What this implies is that you need to use Azure Knowledge Manufacturing facility to create and schedule pipelines (data-driven workflows) that may absorb information from totally different information shops. Azure Knowledge Manufacturing facility also can course of and rework information utilizing compute companies comparable to Azure HDInsight Hadoop, Spark, Azure Knowledge Lake Analytics, and Azure Machine Studying. Additionally, you possibly can publish output information to information shops comparable to Azure SQL Knowledge Warehouse, which may then be consumed by enterprise intelligence (BI) functions.
Briefly, Azure Knowledge Manufacturing facility permits companies to prepare uncooked information into significant information shops and information lakes, thus enabling companies to make higher selections.
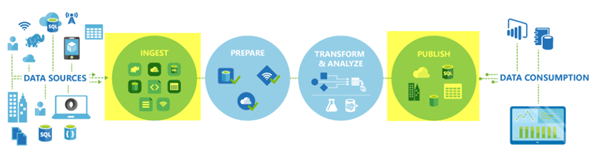
Azure Knowledge Manufacturing facility’s pipelines usually perform the next 4 steps,

Join and acquire
When constructing an info manufacturing system, step one is to hook up with all of the required sources of knowledge. This information could be structured, unstructured and semi-structured. It may be situated on-site or within the cloud and arrives at totally different speeds and intervals. You additionally want to hook up with the sources of knowledge processing, comparable to databases, file shares, software-as-a-service, and FTP net companies. When you’ve related to all of the sources of each the information and the processing, then it’s essential transfer the information to a centralized location so it may be processed.
It’s completely doable for an organization to do all this by constructing customized information motion elements or by writing customized companies. Nonetheless, such techniques are troublesome to combine and keep in addition to being costly. In distinction, a completely managed service can supply the next degree of monitoring, alerts, and controls.
As a substitute of constructing customized information motion elements, Azure Knowledge Manufacturing facility lets you transfer information from on-premises information retailer, in addition to cloud information shops to a centralized information retailer just by utilizing its Copy Exercise (described under).
Copy Exercise performs the next steps,

- It reads information from a supply information retailer.
- It performs serialization/deserialization, compression/decompression, column mapping, amongst others.
- It writes the information to the vacation spot information retailer.
Rework and enrich
HDInsight Hadoop, Spark, Knowledge Lake Analytics, and Machine Studying can be utilized to course of or rework the information as soon as the information is in a centralized information retailer. The remodeled information could be produced in keeping with a controllable and maintainable schedule.
Publish
As soon as the information has been refined, it may be loaded into an analytics engine comparable to Azure Knowledge Warehouse, Azure SQL Database, Azure CosmosDB. Then you possibly can level on the analytics engine from whichever enterprise intelligence software you employ.
Monitor
When you’ve constructed your information pipeline and refined the information, the actions and pipelines should be monitored for achievement and failure charges. Azure Knowledge Manufacturing facility has built-in assist for pipeline monitoring through Azure Monitor, API, PowerShell, and Log Analytics.
Excessive-level ideas
There are 4 key elements in an Azure Knowledge Manufacturing facility. Collectively these elements present the platform on which you’ll be able to construct data-driven workflows. An Azure subscription may be made up of a number of information factories.
Pipeline
A logical grouping of actions that performs a job is called a pipeline. An information manufacturing unit can have a number of pipelines. For example, a pipeline may include a bunch of actions that takes information from an Azure blob after which runs a Hive question on an HDInsight cluster with the intention to partition the information. Utilizing a pipeline means that you may handle the actions as a set, fairly than individually. The actions can run sequentially or independently in parallel, relying in your wants.
Exercise
An exercise is a processing step in a pipeline. Azure Knowledge Manufacturing facility helps three forms of actions: information motion actions, information transformation actions, and management actions.
Datasets
Datasets characterize information buildings throughout the information shops. They level to the information you wish to use as inputs or outputs in your actions.
Linked companies
Linked companies are just like connections strings. They outline the connection info which the Knowledge Manufacturing facility wants so as to have the ability to connect with exterior sources.
Linked companies have two functions:
They’re used to characterize an information retailer that features, amongst others, in on-premises SQL Server databases, Oracle databases, file shares, or Azure blob storage accounts.
Linked companies are additionally used to characterize a compute useful resource which may host the execution of an exercise.
Triggers
The unit of processing that determines when a pipeline execution must be kicked off is represented by a set off. There are a number of various kinds of triggers, relying on the kind of occasion.
Pipeline runs
A pipeline run is an occasion of the pipeline execution. Pipelines embody parameters and a pipeline run is instantiated by passing arguments to those parameters. You’ll be able to go the arguments throughout the set off definition, or manually.
Parameters
Parameters are outlined within the pipeline and they’re key-value pairs of read-only execution. Actions throughout the pipeline eat the parameter values. Each datasets and linked companies are forms of parameters.
Management movement
Management movement is how the pipeline actions are organised. This will embody placing the actions in a sequence, branching, in addition to defining parameters within the pipeline and passing arguments to those parameters.
Supported areas
Azure Knowledge Manufacturing facility is at the moment accessible within the following areas.
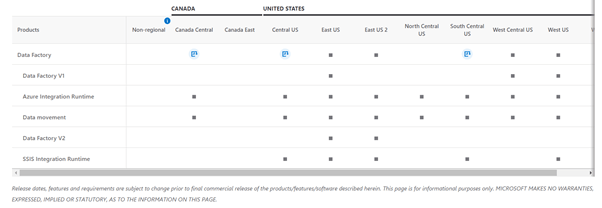
Though Azure Knowledge Manufacturing facility is at the moment accessible in solely sure areas, it could actually nonetheless mean you can transfer and course of information utilizing compute companies in different areas. In case your information retailer is behind a firewall, then a Self-hosted Integration Runtime which is put in in your on-premises setting can be utilized to maneuver the information as an alternative.
In sensible phrases, which means that in case your compute environments are working out of Western Europe, you need to use an Azure Knowledge Manufacturing facility in East US or East US 2 to schedule jobs in your compute setting in Western Europe. The size of time it takes to run the job in your computing setting doesn’t change because of this.
If you wish to study extra concerning the info on this article., listed here are some nice hyperlinks so that you can begin with!
Official documentation for Azure Knowledge Manufacturing facility
Microsoft labs for Azure Knowledge Manufacturing facility
Video – Azure Knowledge Manufacturing facility Overview