We’re all conscious that SQL is usually used to question structured information however in Synapse Analytics we are able to use SQL to question unstructured information saved in recordsdata like CSV, parquet, and many others utilizing OPENROWSET perform and it is likely one of the many options that may be executed utilizing synapse analytics. On this week’s article, we are going to take a look at how it may be executed in a number of steps.
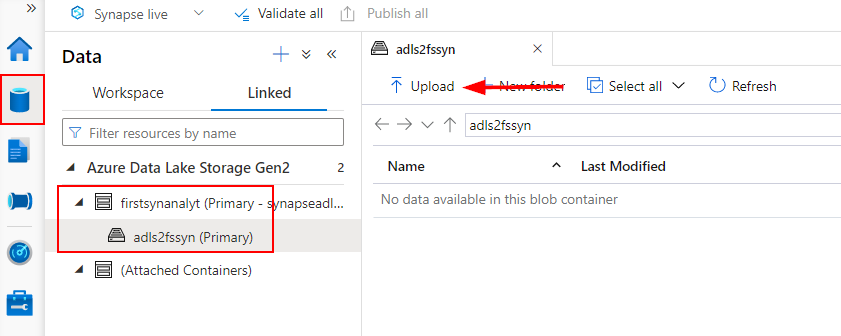
Open the Synapse studio and click on the ‘Knowledge’ tab obtainable on the left nook as proven under. That is the place you possibly can see all of your linked information lakes and containers. In my case I’ve a container already created to my linked ADLS storage therefore we will probably be utilizing that. Presently, there are not any recordsdata obtainable in that so we are going to add a CSV file from my native storage for this demo.
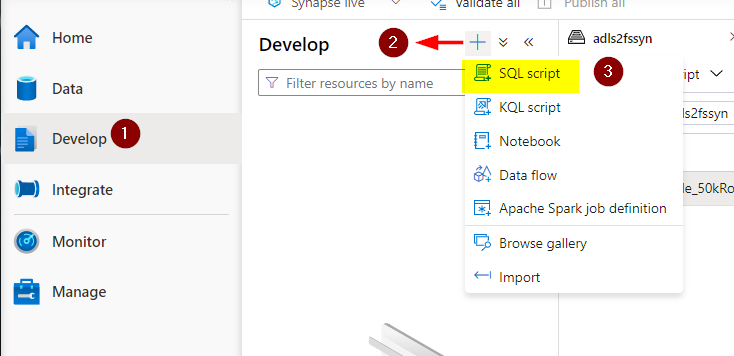
After loading your pattern file to the ADLS storage which in-turn linked to your workspace, transfer on to the ‘Develop’ tab on the left nook under the information tab that we labored on throughout the earlier part. Now you possibly can click on the ‘add’ image and create a SQL Script since our process is to question the recordsdata in ADLS by SQL question.
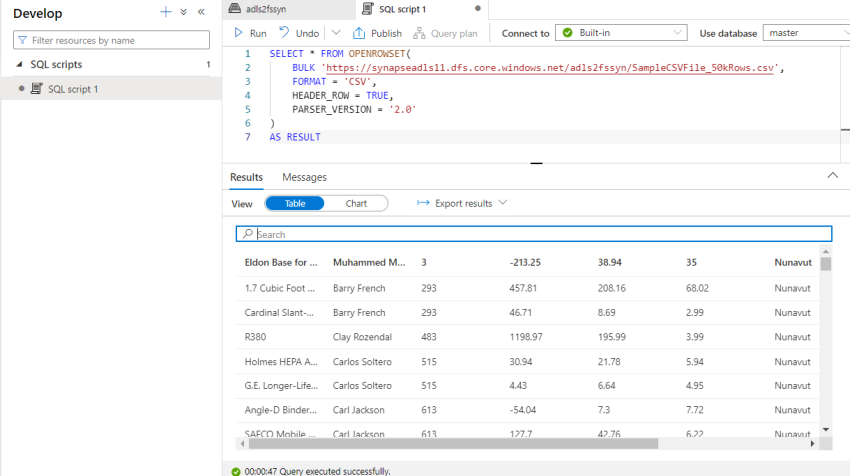
Now it’s all set, we are able to go forward and begin utilizing SQL. Like our typical SQL, you possibly can question with a further key phrase name OPENROWSET which is able to assist to fetch particulars from file and show in a tabular format.
SELECT * FROM OPENROWSET(
BULK 'https://synapeadls11.dfs.core.home windows.web/adl2fssyn/SampleCSVFile_50kRows.csv',
FORMAT = 'CSV',
HEADER_ROW = TRUE,
PARSER_VERSION = '2.0'
)
AS RESULT
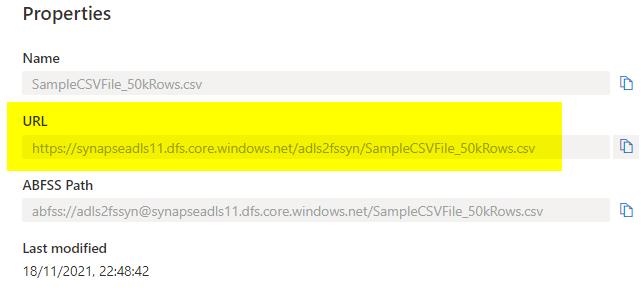
The ‘BULK’ discipline is the place you could present the file path for the file you could have saved in ADLS. Use the under technique to seek out that out out of your connected storage.
I’ve queried your complete desk with 50 thousand rows and because it was first time execution, it took some time. You can even restrict it to few hundred rows by modifying the script to fit your requirement and it’s easy as you do for every other SQL question.
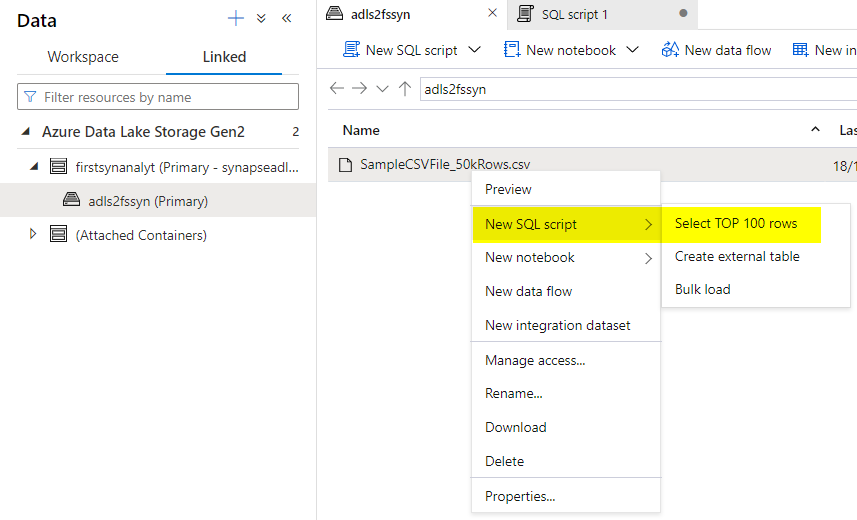
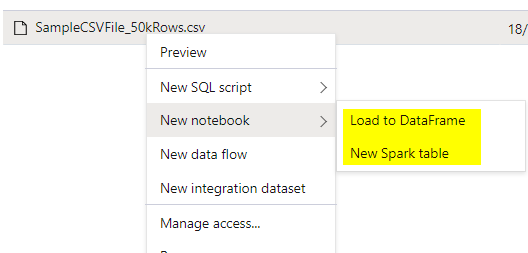
However in case you are too lazy to kind within the script or are GUI savvy? Microsoft azure has choice for you too! Simply go to the ADLS storage and proper click on the place you’ll get choices to pick out solely high 100 rows. Not solely which you can create the file straight into an exterior desk, new spark desk or perhaps a spark dataframe.
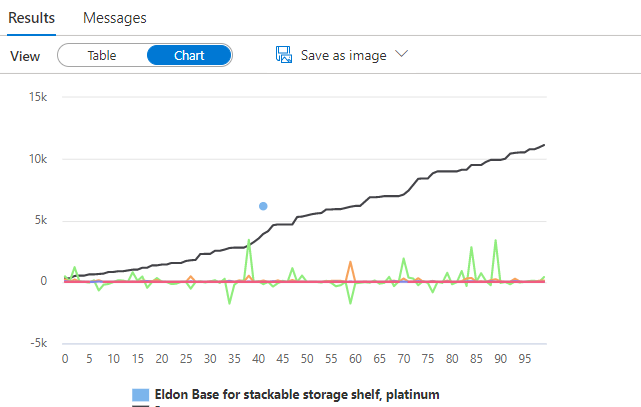
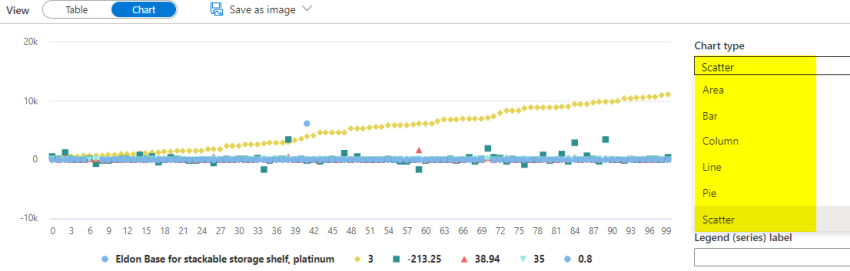
Among the finest components of synapse studio is that you’ve got choice to entry the in-built visualization function obtainable within the outcomes pane by which completely different chart sorts with completely different columns might be created. This will probably be significantly helpful and time saving when you could create a chart and don’t need to save the file and transfer information to a separate utility only for this objective.
Abstract
We noticed the right way to question unstructured file saved in information lake by SQL in azure synapse analytics. There is a vital idea when working with information in azure synapse analytics to pick out between Serverless and Devoted SQL Swimming pools primarily based on the requirement. Although my earlier article clarify it theoretically, I’ll write about it in upcoming article with an actual time state of affairs.