Planning A Catastrophe Restoration Technique On Microsoft Azure – Defining Restoration Necessities
Introduction
Welcome to the sequence of designing a catastrophe restoration technique on Microsoft. Azure and the preliminary module decide these stipulations. Learn the way to find out therapeutic necessities. Due to this fact, for example, we are going to speak about easy methods to deploy resiliency techniques. After that, we are going to take a look at easy methods to work with knowledge backup on the Azure cloud. Then, for Azure functions, we are going to see extra failure evaluation. Then we are going to deal with creating Andrea’s replication plan, and eventually, we are going to wrap up the complete course. We’ll speak about designing and implementing catastrophe restoration for Azure functions on this module. RTO, RPO, and RLO are among the phrases we are going to go over. We will even take a look at how catastrophe restoration works for among the hottest Azure PaaS providers, similar to Azure App Service, Azure SQL, Cosmos DB, and storage accounts. Then we are going to take a look at easy methods to use the site visitors supervisor service.
Defining Restoration Necessities
Resiliency guidelines for particular azure providers
We’ll deal with phrases like resiliency and catastrophe restoration, in addition to discover a number of widespread Azure providers. We’ll start with an evidence of two key phrases catastrophe restoration and resiliency.
Catastrophe restoration
After an outage, catastrophe restoration particulars the processes used to revive the answer’s availability. It refers back to the technique of returning techniques and knowledge to a beforehand acceptable state after a partial or full failure brought on by pure or technical occasions. Think about the likelihood that somebody eliminated a desk in a database or that our net API stopped working for no obvious cause. From right here, we should do all doable to revive the answer’s availability. Because of this, we should not solely decide what occurred but additionally make this resolution out there to end-users.
Resiliency
It’s the potential of a system to recuperate from failures and proceed to perform after a failure has occurred. You will need to needless to say every expertise has its personal set of failure modes whereas creating and deploying software options.
There are some vital inquiries to ask associated to resiliency and catastrophe restoration:
- How a lot can we spend money on making our software extremely out there?
- How a lot does potential downtime price our enterprise?
- What are our buyer’s availability necessities?
Tips on how to implement resiliency?
Figuring out subscription and repair necessities
The method of figuring out subscription and repair necessities entails various key processes. Sure sources, such because the variety of useful resource teams, programs, and storage accounts, are restricted in each Azure subscription. We now have the choice of making a brand new Azure subscription and provisioning adequate sources there if our software necessities surpass different subscription constraints.
Apply resilience methods
Resilience methods are being carried out. Retried Transient Failures is one among these options. Transcend failures might be brought on by a brief lack of community connectivity, a dropped database connection, or a interval when the service is busy, and are often mounted by retrying the request. An alternative choice is to make use of synchronous operations as usually as possible. Whereas the colour waits for the method to complete, synchronous processes would possibly monopolize sources and hinder different operations. At any time when possible, design every portion of your programmed to observe for synchronous processes.
Plan for utilization patterns
Determine variations in necessities throughout crucial and non-critical durations. Are there any instances when the system have to be up and working? For instance, a tax submitting software can fail throughout submitting deadlines and a video streaming service shouldn’t lag throughout dwell occasions. On this scenario weighed the fee towards the chance.
Determine distinct workloads
Decide at varied workloads. A number of software workloads are widespread in cloud options. By way of enterprise logic and knowledge storage necessities, a workload is a definite functionality or process that’s logically separated from different duties. For instance, an e-commerce app might have the next workloads: Browse and search a product catalog, create and observe orders, view suggestions. Every workload has completely different necessities for availability, scalability, knowledge consistency, and catastrophe restoration. Make your online business selections by balancing the reason for danger for every workload.
Function within the a number of areas
Function throughout a number of areas within the uncommon event that your software is deployed to a single space, the complete area turns into unavailable. As well as, your software might be inaccessible. This can be in violation of the phrases of your functions. If that’s the case, take into consideration deploying your software program and its service throughout a number of places.
Monitor third-party providers
In case your software depends on a third-party service, outline the place and the way the service can fail, in addition to the affect failures may have in your software.
Apply load balancing
A site visitors administration system like Azure Visitors Supervisor is required to use load balancing to load stability site visitors between areas. By eradicating unhealthy situations for extra rotation, load balancing distributes your functions’ requests to wholesome service situations.
Determine doable failure factors
Determine the system’s potential failure websites. Decide the varieties of failures that happen on the appliance, my expertise, and the way this system responds to these failures.
Azure paired areas
An Azure paired area is a location inside a geography that incorporates a number of knowledge facilities. Every Azure area is linked with one other area throughout the identical geography to kind a regional pair. For instance, we are able to deploy our Azure useful resource in two distinct areas within the North Europe and West Europe areas.
Azure regional pairs
A number of regional Pharisees are accessible in azure. Listed here are some extra examples. North China, East China, Central France, South France, Germany, Central Germany, Northeast Germany We are able to see the regional per conceits of two areas on the left facet, and we have now seen these areas Azure knowledge facilities exist. For extra particulars go to: https://docs.microsoft.com/en-us/azure/best-practices-availability-paired-regions
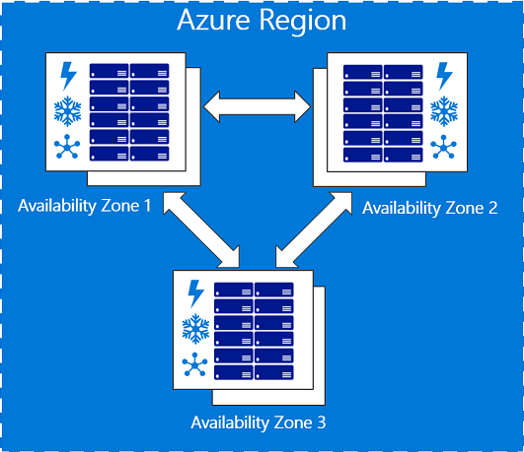
Azure availability zones
Availability Zones are distinctive bodily places inside an Azure area. To make sure resiliency, there’s a minimal of three separate zones in all enabled areas. We are able to see that we have now an Azure area on the left facet. There are three distinct zones of availability. We should still use two of the zones if one turns into unavailable.
Azure PaaS Providers
Azure Internet app providers, Azure SQL Database, Azure Cosmos DB, and Azure storage account all provide PaaS providers. We is not going to go into element concerning the options that every service offers. We’ll discuss concerning the providers and easy methods to make them extra resilient and out there.

Azure Internet App (App providers)
Azure net app providers, Internet functions, Relaxation APIs, and cell backend can all be hosted utilizing this HTTP-based service. It helps quite a lot of languages and frameworks, together with
We are able to lengthen Azure net app service horizontally with quite a few situations and vertically by including energy to some sources, similar to reminiscence or CPU, on a world scale with excessive availability.
Azure SQL Database
Azure SQL Database is a relational database which may be used for something. It’s an Azure managed service that lets you deal with each relational and non-relational constructions like
It additionally has superior monitoring and troubleshooting capabilities.
Azure Cosmos DB
Cosmos DB is a globally distributed multi-model database service offered by Azure. It offers knowledge entry by way of quite a lot of APIs, like
It permits for elastic and unbiased scaling of throughput and storage throughout varied Azure areas internationally.
Azure Storage Account
A Microsoft Azure storage account is a cloud storage resolution for storing present knowledge. Eventualities of those knowledge providers are included in Azure storage.
- Azure blobs
- Azure recordsdata
- Azure Queues
- Azure tables
Resiliency guidelines for Azure App Service
Now, there’s a particular resiliency guidelines for every of those providers. For instance, we must always select the usual or premium tier for the Azure Internet App service. This tier helps staging slots and automatic backups. Due to this fact, if one thing goes mistaken in the course of the deployment, we are able to revert to a earlier model of the appliance.
It is usually a good suggestion to keep away from scaling up or down. Relatively, we must always select a tier and prompt dimension that match our efficiency wants beneath the same old load, then scale out the situations to deal with modifications in site visitors quantity. Scaling up and down could cause an software to hold, which might be problematic for finish customers.
Create manufacturing and check app service plans individually. Slots on our manufacturing deployment shouldn’t be used to check all apps in the identical app service plan. If we use the identical digital machine situations for manufacturing and check deployments, it may well have a detrimental affect on the manufacturing deployment. For instance, shifting check deployments right into a separate plan reduces the lifetime of the manufacturing facet. They’re simply accessible within the manufacturing model.
The logging of diagnostics is one other essential side of our resiliency guidelines. We now have enabled logging. We are able to merely observe bugs in our program and, in fact, swiftly ship patches. There are just a few extra factors to be made about resiliency. Please double-check for the azure app service; nonetheless, listed below are some key examples.
Resiliency guidelines for Azure SQL Database
On the subject of the resiliency guidelines for Azure SQL databases, there are just a few key points to think about, similar to whether or not to make use of the usual or premium tier. After 45 days, these tiers have an extended time limit restore length.
SQL database auditing must also be enabled. Auditing is helpful for detecting hostile assaults and human faults. Lively geo-replication must also be used to construct a readable secondary in a separate area. We are able to do a guide failover to our secondary database if our main database fails or must be taken offline. Till we failover, the secondary database stays read-only.
Time limit restore must also be used to recuperate from human error. Restore returns our database to a earlier state. These parts are crucial since our software turns into nugatory with out adequate database entry.
Resiliency guidelines for Azure Cosmos DB
On the subject of resiliency, Guidelines for cosmos DB. Two key components ought to be thought of when utilizing Azure Cosmos DB. The database ought to be replicated between areas. Because of this, even when one area is unavailable, we are able to nonetheless entry and browse knowledge from one other. We must also enable multi-master in one other area if desired. We are able to write to many Azure areas on this scenario. It implies that even when one area is unavailable, knowledge can nonetheless be written to the opposite.
Resiliency guidelines for Azure Storage Account
The resiliency guidelines for Azure storage accounts additionally has some fascinating factors. We must always make use of re-access geo-redundant storage for software knowledge. This storage replicates knowledge to a secondary area and permits read-only entry from that location. If the first area’s storage fails, this system can learn knowledge from the digital machine discs within the secondary area.
We ought to make use of it as a result of the discs are correctly separated from one another, this offers improved dependability for digital machines in availability units. To. Keep away from having a single level of failure with regards to Queue storage. For Queue storage, we must always assemble a backup Queue in one other area. We must always as an alternative set up a backup Queue. In a unique area’s storage account. This system can use the backup queue if there’s a storage outage. Till the first area is out there.
Decide and Doc RTO, RPO, and RLO Restoration Necessities
Restoration time goal RTO
Allow us to start with the RTO (restoration time goal). That is the period of time and repair stage inside which our enterprise course of have to be recovered following a catastrophe to keep away from unacceptably unfavourable repercussions. Affiliate with a break within the move of occasions.
Which means that within the occasion of a catastrophe, similar to a white system an infection or a consumer destroying manufacturing knowledge, the RTO is the period of time it’s going to take to recuperate from the disaster and restore knowledge and functions. The purpose of recuperation time is sort of essential. Think about the case of a banking software that goes down in flames. For instance, is it higher to delete the complete database with the consumer’s desk or solely a desk with the consumer’s knowledge? Customers who’re unable to check in to this system are unable to entry important knowledge. We should do every little thing doable to return the system to a state the place customers can entry it.

Restoration Level Goal (RPO)
The purpose of the restoration level RPO refers back to the period of time that may move throughout a disruption earlier than the quantity of knowledge misplaced throughout that point exceeds the enterprise’s necessities. Most Allowable Threshold for Continuity Plans For instance, if the final good copy of knowledge out there throughout an outage is from 18 hours in the past and the R P O for this enterprise is 20 hours, we’re nonetheless throughout the bounds of the enterprise continuity plans RPO. To place it one other approach, that is the answer to the query. Given the quantity of knowledge misplaced throughout that point, as much as what level would possibly the enterprise course of restoration proceed to label?
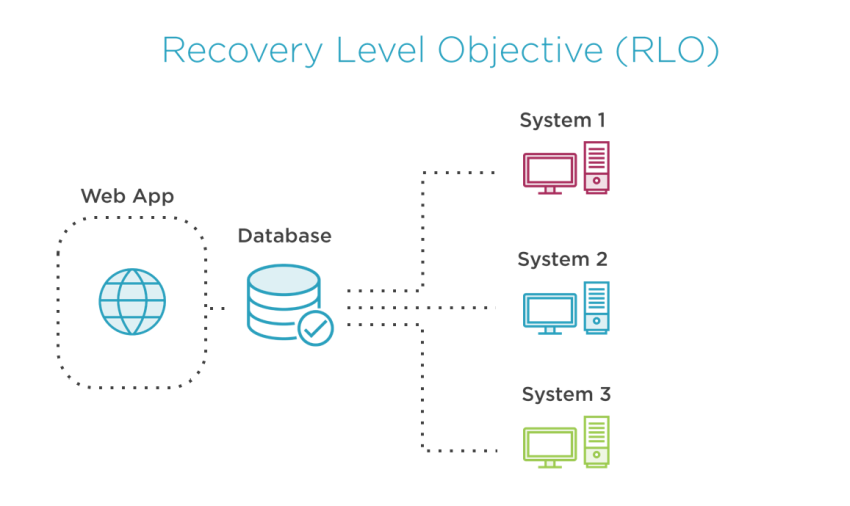
Restoration Degree Goal (RLO)
RLO specifies the extent of granularity with which knowledge have to be recovered, similar to the complete occasion, database, or group of databases, or chosen tables all through the complete system. For instance, we should decide whether or not we have to restore the Internet software, or whether or not we have to recuperate the database construction, or whether or not we have to recuperate the complete system.
Backup and Catastrophe Restoration for Azure Utility
Catastrophe restoration plan
Many Azure providers have built-in resiliency and availability traits. The catastrophe restoration plan is probably going to enhance if every service is evaluated individually. Azure SQL Database, for instance, helps Geo-replication. We should still entry the info from a second Azure area if the info is unavailable in a single Azure area because of the deletion of a desk, similar to a consumer’s desk. That’s fairly useful. An alternative choice is Azure Cosmos DB, which permits us to allow geo-replication in addition to write to a number of areas. When tragedy strikes, it is usually a good suggestion to construct a catastrophe restoration plan as soon as our treatment is out there. Allow us to take a look at among the features of such a plan.
- Consider the enterprise affect of software failures
- Automate the method as a lot as doable
- Doc the method, particularly any guide steps
- Select a cross-region restoration structure
- Carry out common catastrophe simulations to validate and enhance the plan
Primarily, we should assess the monetary impact of software failures. For instance, we must always reply to a fundamental inquiry. What occurs if the appliance fails to perform? We’ll virtually definitely lose cash. We must also attempt to automate as a lot of the process as possible. For instance, we must always have computerized launch pipelines in place to permit for fast restoration. We must also doc the method, notably any guide processes, and provides the workforce members express directions on easy methods to recuperate from the failure. We must also choose a restoration structure that’s relevant throughout areas. That is one thing I already talked about. That we must always deploy our resolution throughout a number of areas to allow catastrophe restoration. And we must also run catastrophe simulations recurrently to check and enhance the technique.
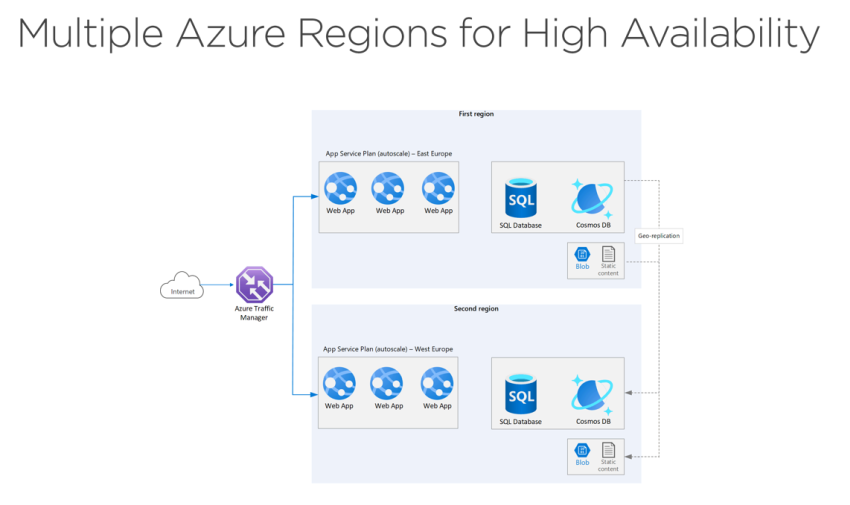
A number of Azure areas for prime availability
Think about the usage of a number of Azure areas to realize excessive availability. In two areas, we have now Internet apps. SQL Database, Cosmos DB, and Azure Storage are additionally out there. When a Internet software within the First Area goes down, the site visitors supervisor can root Tropic by means of the Second Area, giving our resolution most availability.
Information corruption and restoration
It’s a good suggestion to maintain backups whereas coping with knowledge harm and restoration. Backups defend towards the lack of an software part attributable to knowledge corruption or inadvertent deletion; the frequency with which the backup process is completed units the restoration level goal RPO. If knowledge in Azure Storage or SQL databases are corrupted or deleted within the main, Azure shops it 3 times in several full domains in the identical area. All modifications are copied and replicated to the opposite copies.
Allow us to take a look at some high-availability options,
Azure App Service, one of many Azure providers, might scale as much as 30 digital machine situations. Within the common and premium ranges, it additionally helps staging slots and automatic backups. We are able to maintain the final identified good deployment with their deployment slots. If there is a matter, will probably be found later. There may be a straightforward approach to return to the final identified good model.
Your software helps Azure Cosmos DB in all areas. We are able to nonetheless entry knowledge from one other area if knowledge from one is unavailable. The information was duplicated within the second area. Azure Cosmos DB additionally helps a number of proper areas. It implies that even when one area is inaccessible for the info we’d like, we should still write it to a different. After our failover, the consumer, like violate decay, submits the right request to the present correct space.
On the subject of excessive availability with Azure SQL Databases, energetic geo-replication is out there, which lets you create a readable secondary reproduction. There might be as much as 4 readable secondary replicas in every zone. If the first database fails or must be taken offline, we are able to change to a secondary database. Learn-only entry
For Azure storage accounts, Geo Redundant Storage offers excessive availability. It replicates the info to a secondary area and offers the secondary area read-only entry to the info.
If the first space’s storage fails, this system can learn knowledge from the secondary area. To make sure sturdiness and excessive availability, the info within the Microsoft Azure storage account is all the time replicated.
Wrap Up
On this article, we mentioned the next, resiliency guidelines for particular azure providers like Azure drop service, Azure SQL Database, Cosmos DB, and storage account. We clarify phrases like RTO, RPO, and RLO. Within the subsequent article, we are going to look into particulars of knowledge backups on Microsoft Azure