Introduction
On this article, we are going to verify how we will copy new and altered recordsdata based mostly on the final modification date. The steps have been given under with explanations and screenshots. As of this writing, Azure Information Manufacturing unit helps solely the next file codecs, however we will make sure that extra codecs will likely be added sooner or later.
- Avro format
- Binary format
- Delimited textual content format
- Excel format
- JSON format
- ORC format
- Parquet format
- XML format
Incremental file copy
In knowledge integration, incremental copy of knowledge or recordsdata is a standard state of affairs. An incremental copy might be achieved from the database or recordsdata. For copying from the database, we will use watermark or by utilizing CDC (Change knowledge seize) expertise. However right here we’re going to see do incremental copy on file degree utilizing final modified time from azure blob storage.
Create Storage Account
I’ve created a easy blob storage account for holding all my recordsdata. You’ll be able to create a brand new one if you would like(confer with my earlier blogs on create one) or use the one you’ve got presently.
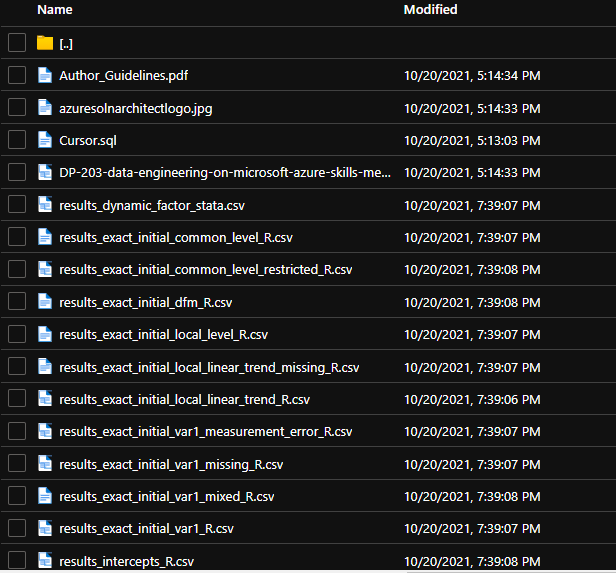
As soon as contained in the blob I’ve created a container referred to as ‘inputfiles’ and uploaded some recordsdata into it.
Upon getting all of the recordsdata prepared contained in the blob create a brand new azure knowledge manufacturing unit occasion or use an present one. I’m creating a brand new one since I’ve deleted all of the sources already. As ordinary, as soon as created go to the azure knowledge manufacturing unit studio and go into writer mode; the little pencil icon on the left-hand facet. In case you have any doubts or wish to see create one, confer with my earlier blogs the place step-by-step directions have been given with screenshots.
The following step is to map the blob we created earlier to create a brand new linked service that can be utilized to name it contained in the pipeline. I’ve lined it in my earlier article therefore I’ll skip it.
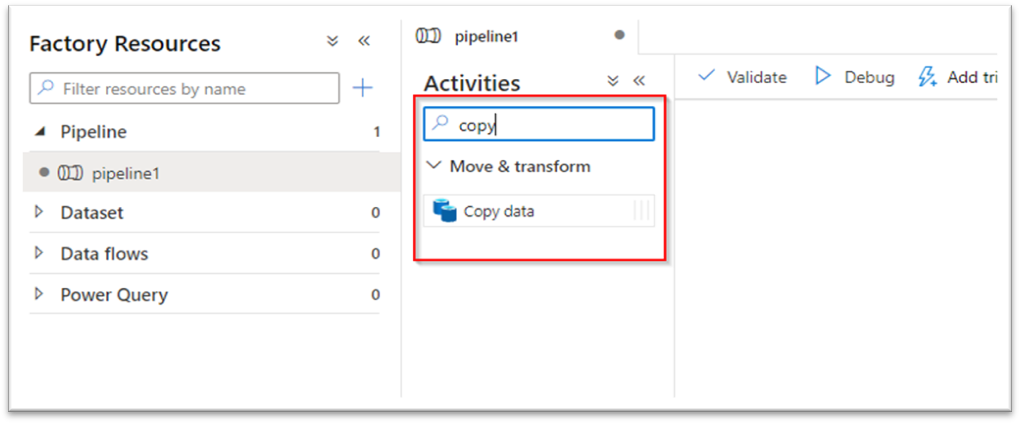
Now head again to the writer tab to create a brand new pipeline. Kind ‘Copy’ within the search tab and drag it to the canvas; It is with this we’re going to carry out incremental file copy.
The 2 vital steps are to configure the ‘Supply’ and ‘Sink’ (Supply and Vacation spot) to be able to copy the recordsdata.
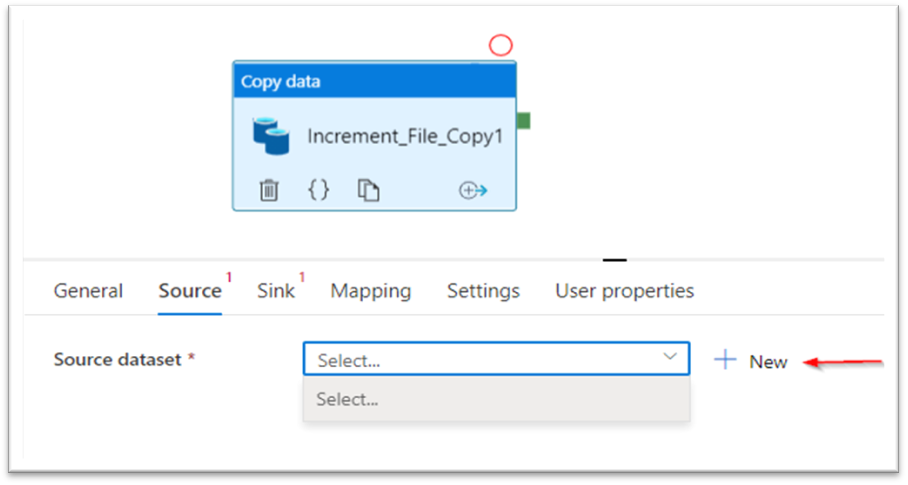

Flick thru the blob location the place the recordsdata have been saved. One factor to notice right here is I’m not giving any file identify or extensions right here as I’m offering these particulars solely within the wildcard part like within the subsequent screenshot.
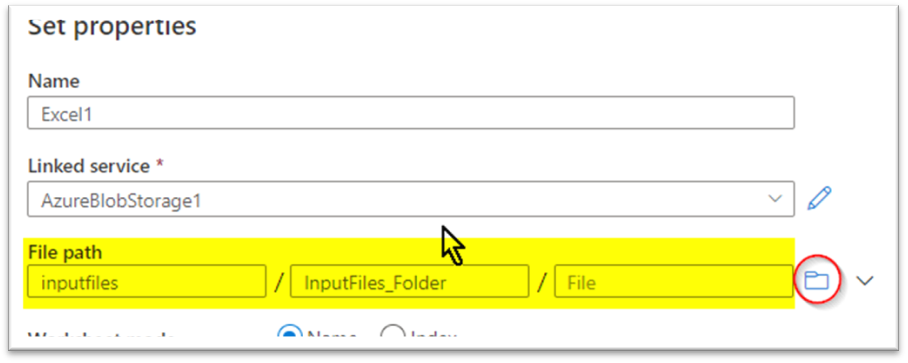
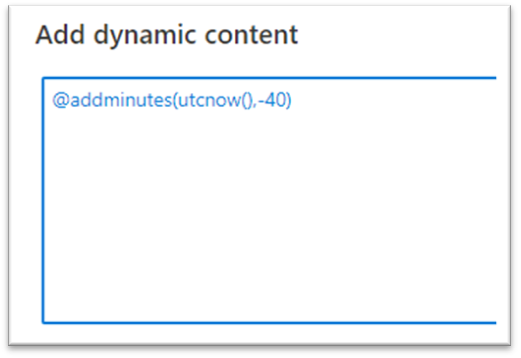
I chosen the wildcard path and talked about all of the recordsdata which might be with the “.csv” extension created inside the final 40 minutes to be copied over from that blob container.
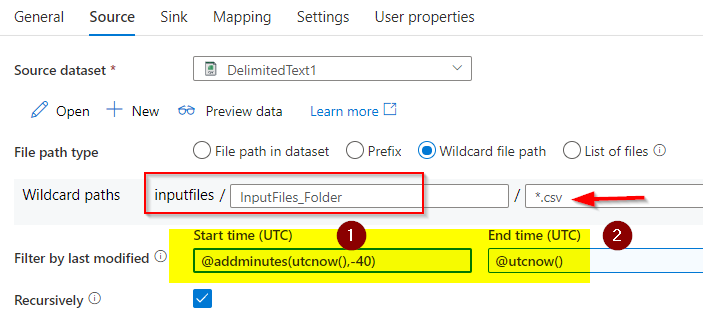
The above picture exhibits how are attempting to select solely recordsdata with .csv extensions which might be created within the final 40 minutes solely.
Begin time is configured as present time (utcnow) minus forty minutes and endtime is the present time.
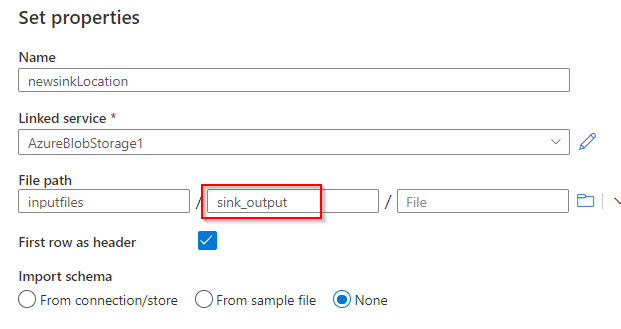
Much like the supply dataset choice now create the sink dataset. There won’t be a folder, however you possibly can present a reputation you need and it is going to be created within the blob storage.
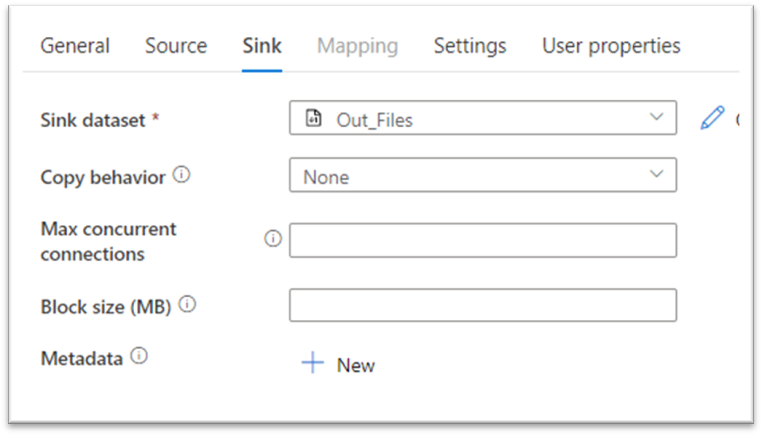
That’s all for the sink configuration, we now have efficiently created the vacation spot now.
It is time to debug and verify how the recordsdata are picked up for a duplicate. Earlier than that, it is higher to take a look at the container first and take a word of the folders, file names, and kinds, so it is going to be simple so that you can discover out the precise copy is profitable or not.
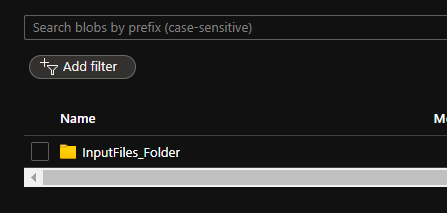
There isn’t a output folder as of now, let’s have a look at how this creates a folder after which copies the recordsdata.
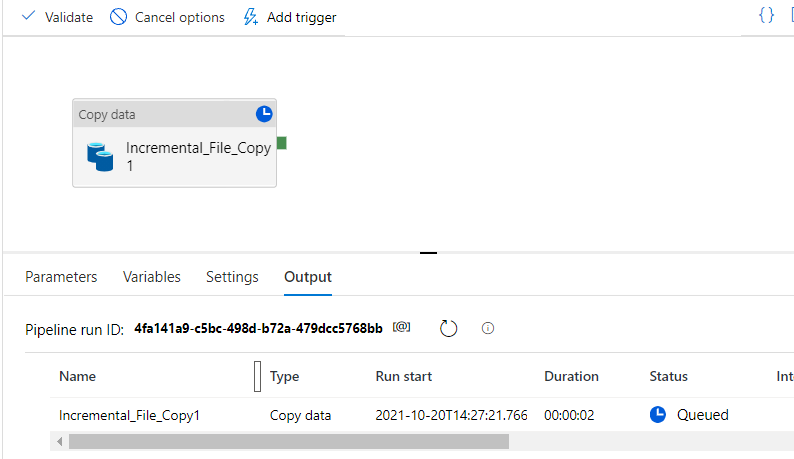
The small eyeglass button over there’ll allow you to see the main points of what number of recordsdata have been processed and the way did it run.
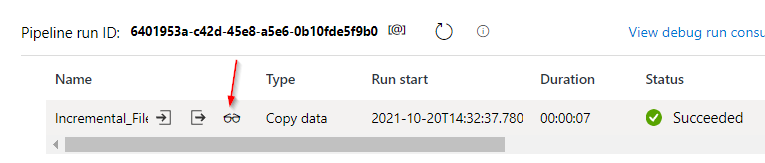
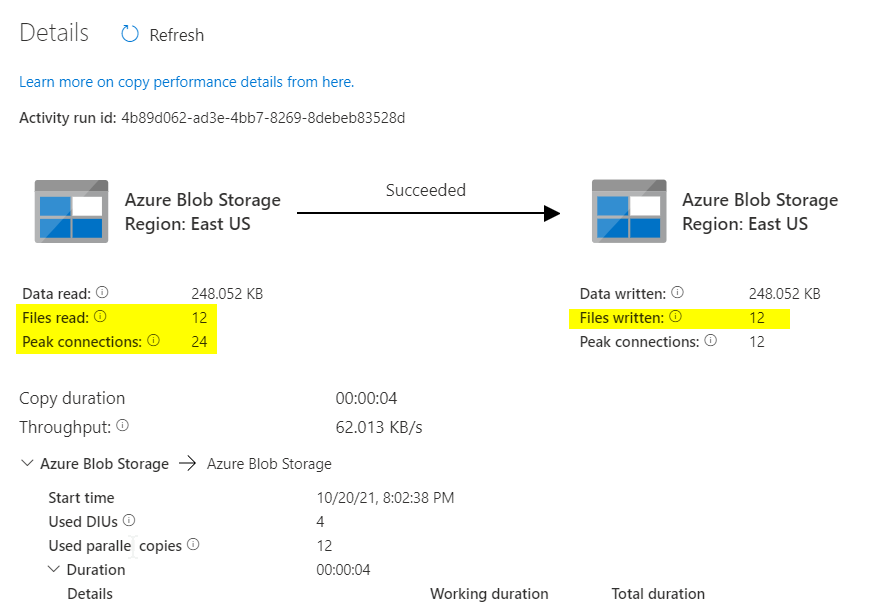
Now the pipeline has been efficiently run, let’s verify the output folder is created and the recordsdata are copied.
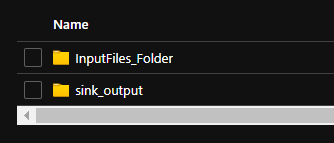
Now that it is all good, go forward and publish the pipeline in your use.
Abstract
We noticed a easy file copy exercise based mostly on the file extension and up to date modification time. How may we leverage the options of the Azure knowledge manufacturing unit pipeline to automate file copy from one location to the opposite? There are many different parameters out there so that you can discover other than days, hours, minutes, seconds, and many others. We’ll meet up with one other attention-grabbing use case within the coming days.
Reference
Microsoft official documentation