How To Use Information Circulate Partitions To Optimize Spark Efficiency In Information Manufacturing facility
Introduction
On this article, we are going to discover the completely different Information movement partition sorts in Azure Information Manufacturing facility. Every partitioning sort supplies particular directions to Spark on easy methods to manage the info after every processing within the cluster. It is a essential step in creating any information transformation because it permits us to optimize the efficiency of our Information movement pipeline.
Challenges
In our earlier article, we realized easy methods to view the processing time by levels and entry the partition chart by enabling the verbose logging within the Information movement exercise. Now, we have to evaluation our information transformation to scale back the transformation time. In every Information movement parts, we are able to change the partition sort. Earlier than we dive into the tutorial, we have to perceive the 5 partition sorts:
- Spherical Robin: Evenly distribute the info throughout the desired variety of partitions. Spark will re-partition the info if the variety of partition adjustments. That is typically used once we would not have a very good column to distribute the info.
- Hash: We outline the columns for use by the hashing perform. A hash worth is generated primarily based on the distinctive column values. Every hash worth is mapped to precisely 1 partition however a number of hash worth could be positioned in a partition. The good thing about this methodology is to group all of the columns with the identical values collectively for downstream processing (like aggregation).
- Dynamic Vary: We outline the columns for use to rearrange the info. Spark will decide the vary of values that may match inside every partition.
- Fastened Vary: We outline the particular circumstances for partitioning the info. Spark will use this as a part of the partition perform.
- Key: The variety of partitions is generated primarily based on the columns outlined. Every distinctive mixture of values will lead to one partition. This could solely be used if the mixtures are restricted and are small.
Tutorial
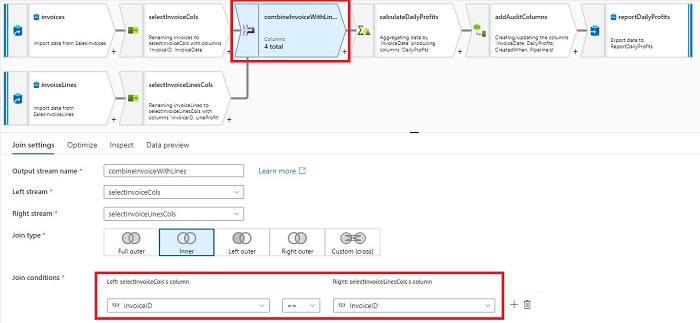
1. Let’s evaluation the info movement we’re utilizing for this tutorial:
- We’ve got 2 supply Azure SQL Tables.
- We’re becoming a member of them utilizing ‘InvoiceID’ to calculate the every day revenue utilizing ‘InvoiceDate’.
- Lastly, we’re including some audit columns and writing the output to a reporting Azure SQL desk.
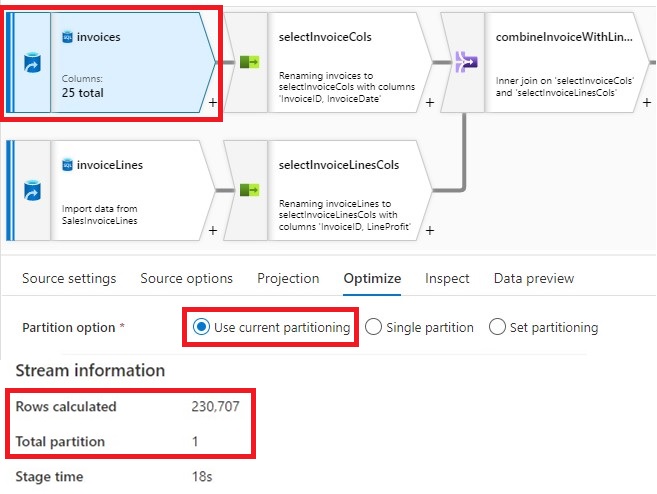
2. Each ‘invoices’ and ‘invoiceLines’ sources are partitioned utilizing ‘Use present partitioning’. When utilizing with possibility with sources, the info is partitioned evenly throughout all of the partitions. A brand new partition is created when the info is about 128 MB. Usually, that is the advisable setting for many sources.
As you possibly can see, in our instance, mapping information movement created only one partition as a result of we do not have plenty of information,
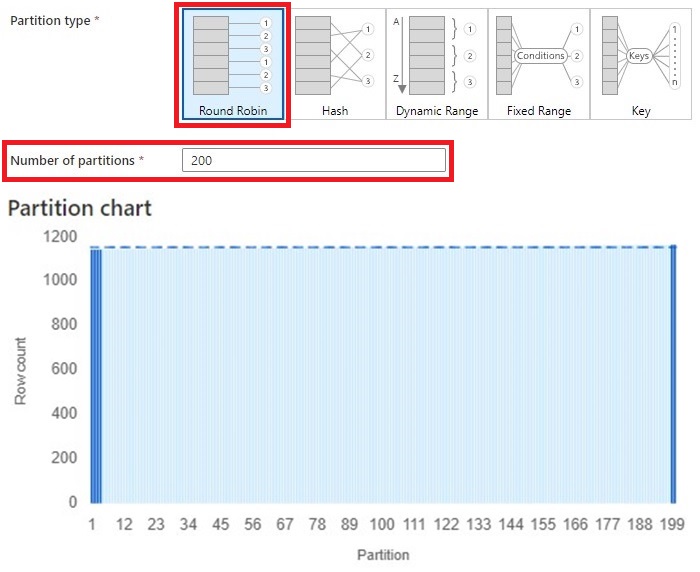
3. Subsequent, we are going to look at completely different partition optimization within the ‘combineInvoiceWithLines’ be a part of factor. First up is ‘Spherical Robin’:
- That is the default choice. We created 200 partitions.
- As anticipated, the info is distributed evenly throughout all partitions.
- To hitch the info and repartition the outcome, it took 2.853s.
- We are going to deal with this as the bottom case for our optimization. We’ve got slightly below 1200 information in every partition.
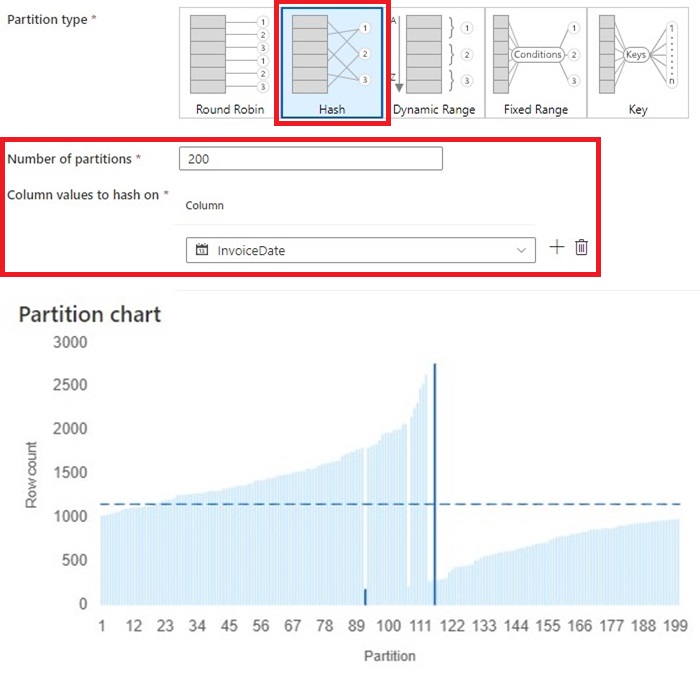
4. The subsequent possibility we have now is ‘Hash’. It is a in style possibility, particularly if we have now a number of columns:
- Once more, we created 200 partitions.
- Since we wish to combination the info primarily based on invoiceDate. We are going to use it for our hash column.
- The outcome exhibits about half of the partitions have increased than common variety of row counts.
- The be a part of and repartition took 1.35s.
- The good thing about this methodology is we all know every invoiceDate is saved in 1 partition. The draw back is we are able to place too many information in a partition. The quantity of knowledge going right into a partition is strictly primarily based on the hashing perform. If our dataset is evenly distributed then this partition methodology will work nice.
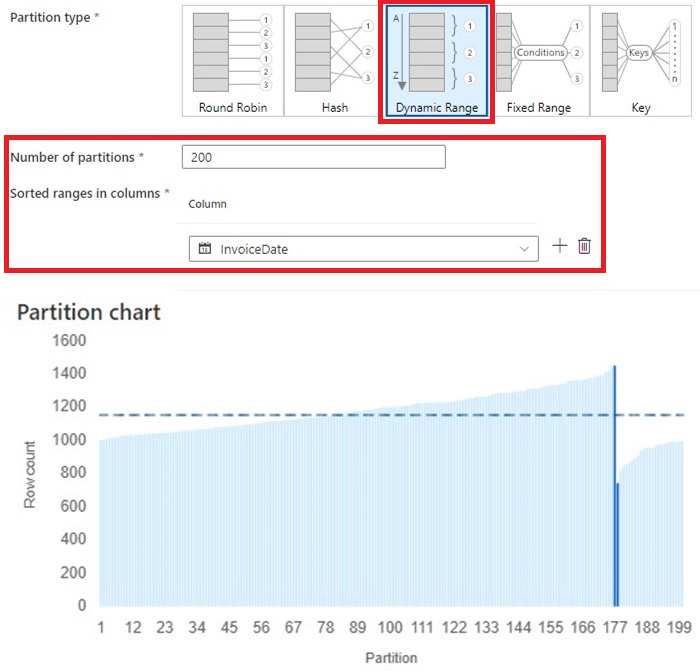
5. Dynamic Vary is similar to Hash partition possibility however Spark will attempt to distribute the info evenly utilizing the column values:
- We’re utilizing 200 partitions and the sorted vary is ‘InvoiceDate’ column.
- The chart appears similar to Hash besides the spikes are a lot smaller and every partition is nearer to the common row depend.
- This course of took 1.129s
- The good thing about this methodology is just like Hash, grouping bill dates collectively whereas permitting Spark to optimize which partition the info must be positioned. This can clean out any main spikes. The draw back reminds if we have now some bill dates with a significate quantity of knowledge higher than different days.
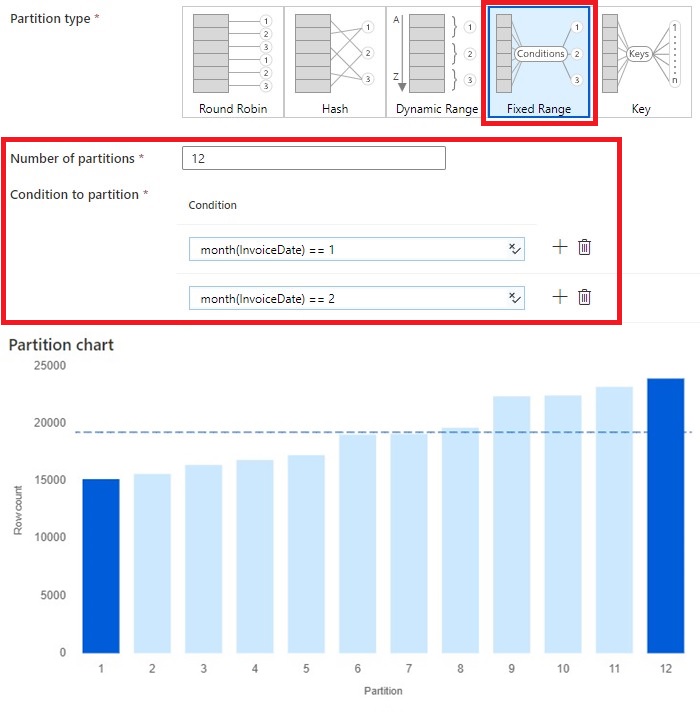
6. Repair Vary requires us to outline the rule for every partition:
- Since repair vary requires me to enter a situation 1 by 1, I created an identical instance utilizing 12 partitions. I outlined a rule utilizing month() perform and created complete of 12 guidelines.
- This course of took 0.269s.
- The profit is this enables full management for the developer to assign a partition to the dataset. The draw back is that this requires higher understanding of the dataset. Because the dataset’s distribution adjustments, it would require adjustments within the partition circumstances.
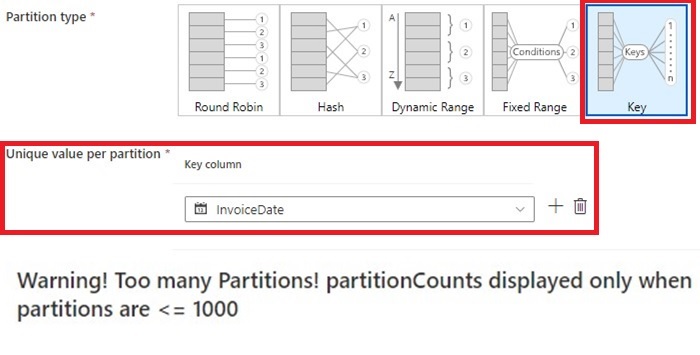
7. The final possibility is Key. On this possibility, we don’t pre-define the variety of partitions. As a substitute, that is created primarily based on the distinctive key values.
- One limitation of this partition methodology is we can not apply any calculation to the partition column. As a substitute, this have to be created in superior, both utilizing derived column or learn in from supply.
- I attempted utilizing InvoiceDate, however it resulted over 1000 partitions. As a substitute, I’d advocate producing a column primarily based on month() and dayofmonth() perform so the utmost partition shall be 366.
- The good thing about this selection is to regulate the variety of partitions primarily based on key columns’ distinctive worth. It is a good use case for information which have a variety of classes. The disadvantage is the overhead of calculating and producing columns for use for this mapping.
Abstract
In conclusion, Mapping information movement supplies 5 partition choices for tuning. Among the choices are simpler to make use of and extra appropriate for on a regular basis use instances. The aim of repartitioning must be to scale back information motion in downstream processes. In consequence, our general levels’ course of time have to be diminished.
Lastly, here’s a desk summarizing the partition choices and my opinion on once we ought to use it.
| Partition sort | Information distribution | Variety of partitions | When to make use of |
| Spherical Robin | Evenly distributed | Consumer outlined | Default, when no good column for distribution. |
| Hash | Primarily based on values in hash columns | Consumer outlined | Multi-value aggregation with a nicely distributed datasets |
| Dynamic Vary | Primarily based on values within the vary columns, Spark will attempt to stability the underutilized partitions | Consumer outlined | Single or Multi-value aggregation. The dataset may not nicely distributed. |
| Fastened Vary | Primarily based on the outlined circumstances | Consumer outlined | Full management over how the info is distributed. Requires good data of the dataset. |
| Key | Primarily based on distinctive values in the important thing columns | Spark generated | When every distinctive worth must be in their very own partition. Solely must be used when the distinctive values are identified and small. |
Comfortable Studying!
References