How To Setup Azure Information Manufacturing facility With Managed Digital Community
Introduction
On this article, we are going to focus on how one can setup Azure Information Manufacturing facility with Managed Digital Community. Azure Information Manufacturing facility (ADF) is a code free Extract-Load-Remodel (ELT) and orchestration service. This PaaS service allows knowledge engineers to create and monitor an information pipeline that may do knowledge ingestion and knowledge transformation. With the intention to preserve all the info actions safe, Azure Information Manufacturing facility gives an choice to run the computes in a devoted Digital Community in your occasion of Information Manufacturing facility.
Challenges
In our earlier article, we created a non-public endpoint for our knowledge lake. Now, our knowledge engineers want to start out growing knowledge pipelines to generate perception for the enterprise groups. The info group has determined to make use of the Azure Information Manufacturing facility and we have to configure it to be secure and safe.
The first causes we have to deploy the Information Manufacturing facility with Managed Digital Community are to maintain the community visitors personal and defend towards knowledge exfiltration. The Execs and Cons of the Managed Digital Community are:
Execs
- This community is managed by Azure and it doesn’t require further overhead from the Information Platform admin group.
- A non-public endpoint may be created with the Managed Digital Community. This may restrict the networking visitors to the personal community.
Cons
- The flexibility to check connection to different companies and debugging require the compute to be began. Historically, a stand-by compute is obtainable from Azure which ends up in a quicker reply time.
- For the reason that compute is devoted to the community, it requires extra planning and pipeline design to make sure the compute can be utilized by a number of processes.
- Since we’re utilizing Non-public Endpoint, further price might be incurred for ingress and egress.
Create a brand new Azure Information Manufacturing facility
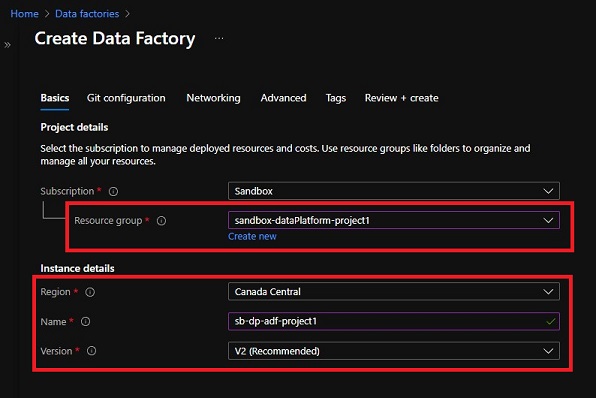
On this tutorial, we are going to create a brand new Azure Information Manufacturing facility for our new tutorial undertaking known as “project1”. To higher set up our initiatives, a brand new useful resource group ‘sandbox-dataPlatform-project1’ is created. We might be creating the brand new Information Manufacturing facility underneath this useful resource group.
Create Information Manufacturing facility – Fundamentals
Choose the useful resource group ‘sandbox-dataPlatform-project1’ and enter within the Information Manufacturing facility identify ‘sb-dp-adf-project1’, then click on ‘Subsequent: Git configuration >’ to proceed.
Create Information Manufacturing facility – Git configuration
We’re going to skip the git setup on this tutorial as we are going to cowl this matter in one other article. For an precise undertaking, I extremely advocate you setup this integration now.
After deciding on ‘Configure Git later’, click on ‘Subsequent: Networking >’ to proceed.
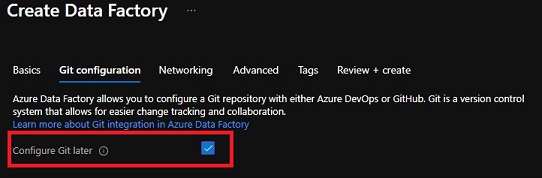
Create Information Manufacturing facility – Networking
In Information Manufacturing facility, the compute and the orchestrator are known as Integration Runtime (IR). An AutoResolveIntegrationRuntime is created as a part of the Information Manufacturing facility deployment. The ‘AutoResolve’ means this Integration runtime will routinely detect the perfect area to make use of based mostly on the vacation spot location.
We wish to allow ‘Managed Digital community’ and join by way of ‘Non-public endpoint’. This may guarantee our integration runtime runs in a separate Digital Community and utilizing Non-public IP. Click on ‘Subsequent: Superior >’ to proceed.
Create Information Manufacturing facility – Superior
On this tab, we are able to specify a customized encryption key. In our case, we are going to let Microsoft handle this so no change is required. Click on ‘Subsequent: Tags >’ to proceed.
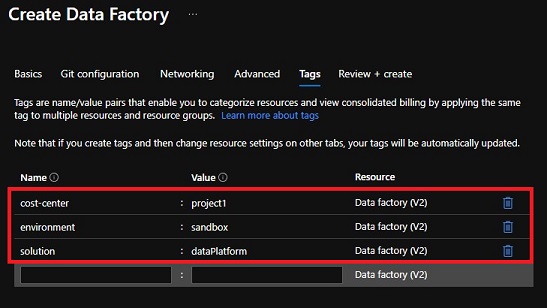
Create Information Manufacturing facility – Tags
Let’s create the tags required for price administration. This knowledge manufacturing facility is created for a selected undertaking, so we are going to assign the cost-center to ‘project1’. Click on on ‘Subsequent: Assessment + create >’ to verify the settings and proceed to creating our Information Manufacturing facility.
Azure Information Manufacturing facility Studio
The ‘project1’ Information Manufacturing facility is created, we have to setup a non-public endpoint to our knowledge lake.
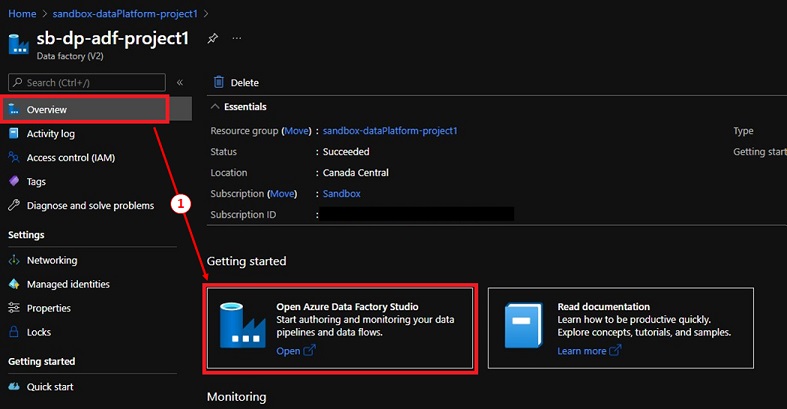
To do that, we have to open the Azure Information Manufacturing facility Studio,
- Navigate to the ‘project1’ Information Manufacturing facility.
- Choose ‘Overview’ and click on on ‘Open Azure Information Manufacturing facility Studio’ hyperlink.
- The ADF Studio will open up in a separate browser tab.
Create an Integration runtime with Interactive Authoring
Sadly, we can not use the Integration Runtime created by our Information Manufacturing facility as a result of it won’t enable us to allow ‘Interactive Authoring’ with the Managed Digital community is enabled.
To work round this, we have to create a brand new Azure Integration Runtime with Interactive Authoring enabled,
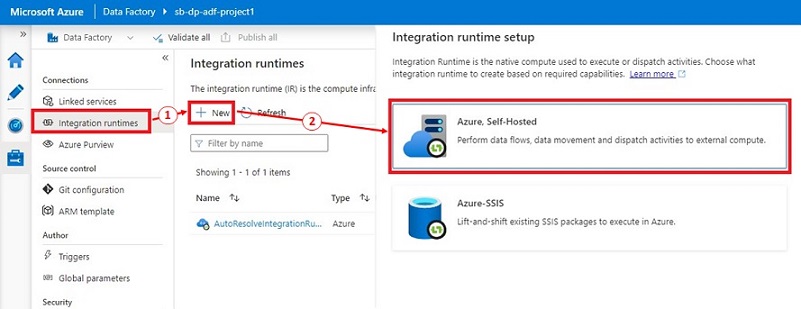
- In Azure Information Manufacturing facility Studio, click on on ‘Handle’ then ‘Integration runtimes’ underneath the ‘Connections’ part.
- Click on on ‘+ New’, a brand new panel is displayed on the best.
- Within the ‘Integration runtime setup’ panel, choose ‘Azure, Self-Hosted’, then click on ‘Proceed’.
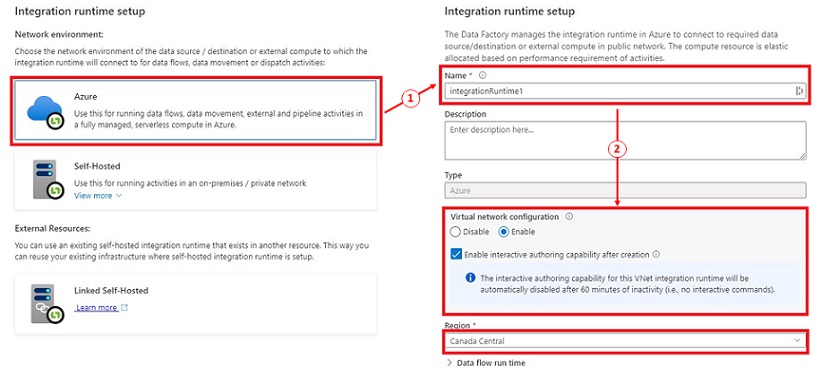
- Choose ‘Azure’ underneath the ‘Community atmosphere’, the clicking ‘Proceed’.
- Present the Integration runtime identify, choose ‘Allow’ underneath Digital community configuration then click on ‘Create’ to proceed.
Azure Information Manufacturing facility Studio – Managed personal endpoint
After the brand new Integration Runtime is created, we are going to setup the Managed personal endpoint with our knowledge lake.
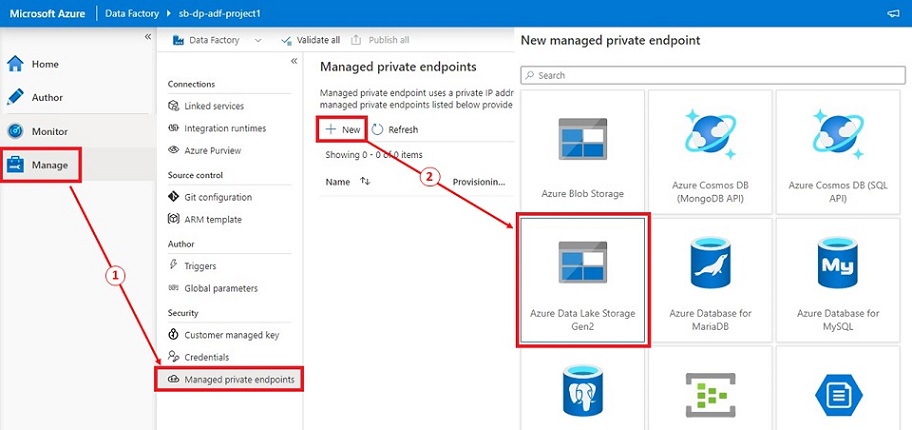
- In Azure Information Manufacturing facility Studio, click on on ‘Handle’ then click on on ‘Managed personal endpoints’ underneath the Safety part.
- Click on ‘+ New’, choose ‘Azure Information Lake Storage Gen2’ and click on ‘Proceed’
- Offering the endpoint identify, choose our knowledge lake then click on ‘Create’ to create the Managed personal endpoints.
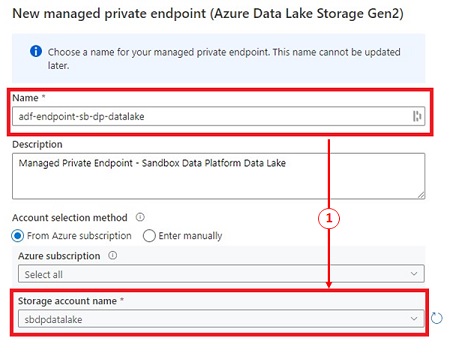
Information Lake – Approve personal endpoint
For safety causes, we now have to manually approve the brand new Non-public Endpoint connection. That is carried out to stop any unauthorized connections.
- Navigate to the info lake, underneath ‘Safety + networking’, click on on ‘Networking’.
- Click on on the ‘Non-public endpoint connections’ tab.
- Choose the reference to the personal endpoint from ‘project1’ adf and click on ‘Approve’.
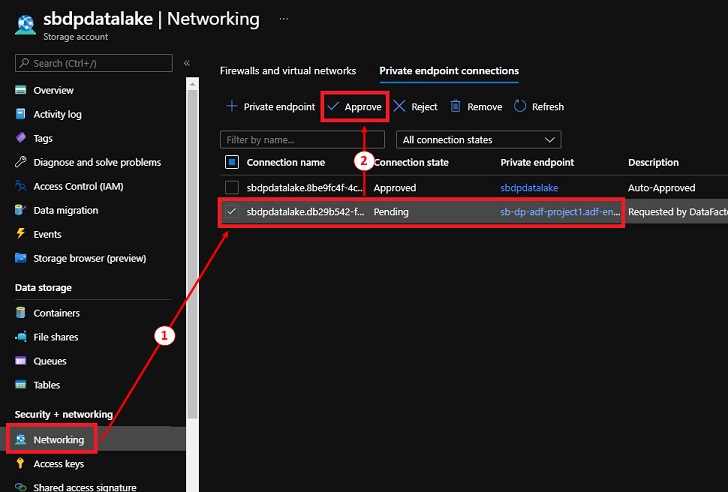
Grant ADF entry to the Information Lake
To maintain this setup easy, I assigned the project1 Information Manufacturing facility ‘Storage Blob Information Contributor’ function to our knowledge lake. This could solely be carried out for testing functions. We must always use assign the permission utilizing Entry management lists (ACL) as an alternative.
- Navigate to the info lake, click on on ‘Entry Management (IAM)’.
- Click on on ‘+ Add’, then ‘Add function task’.
- Choose ‘Storage Blob Information Contributor’, then click on ‘Subsequent’.
- Choose ‘Managed id’ for Assign entry to, then click on on ‘+ Choose members’ underneath Members.
- Choose the ‘project1’ Information Manufacturing facility, click on ‘Choose’ to proceed.
- Click on ‘Assessment + assign’.
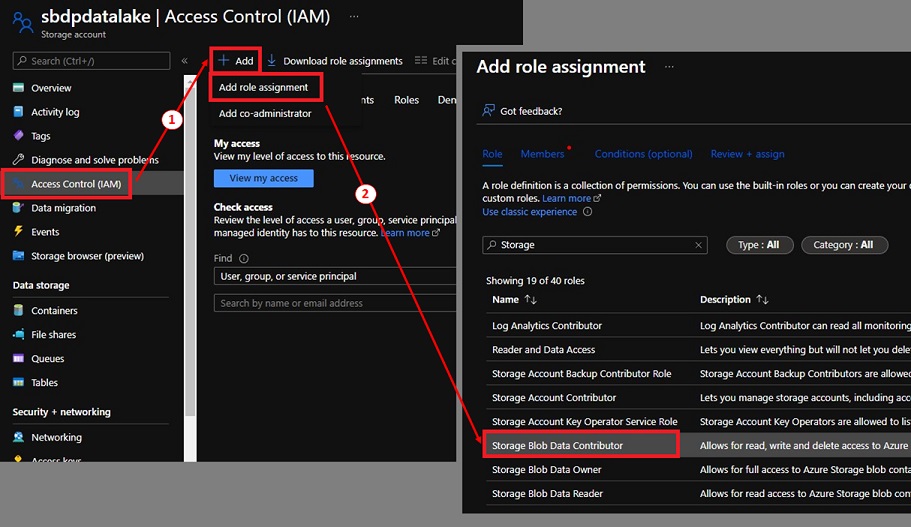
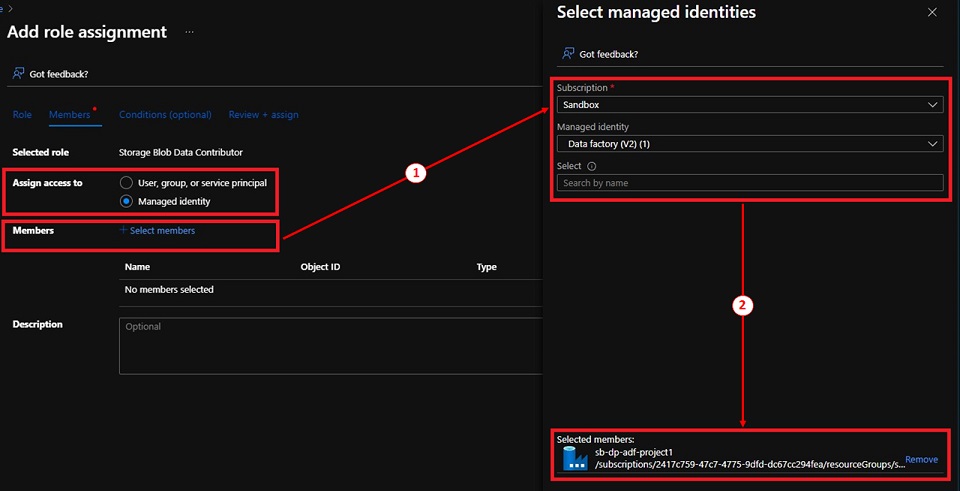
Testing – Information Lake connection
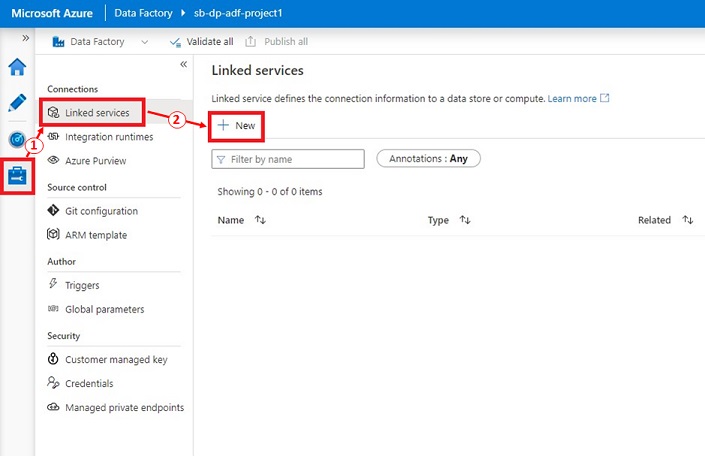
Lastly, we are able to check our Information lake connection utilizing a Linked service. A Linked service is just like a connection string which shops the server identify, authentication strategies, username and passwords data.
- In Azure Information Manufacturing facility Studio, click on on ‘Handle’ then ‘Linked companies’ underneath ‘Connections’ part.
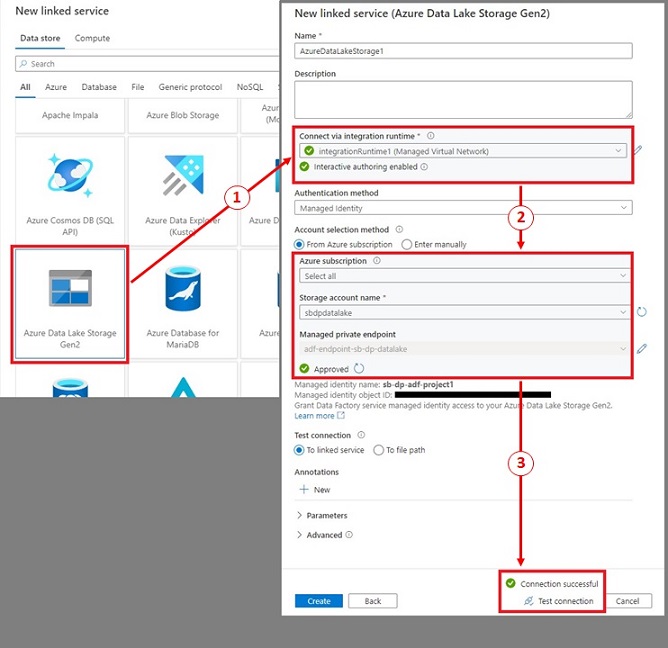
- Click on on ‘+ New’, then choose ‘Azure Information Lake Storage Gen2’. Click on ‘Proceed’ to proceed to the subsequent step.
- Present the Linked service identify, choose the combination runtime we simply created, choose ‘Managed Identification’ for Authentication technique and choose the info lake.
- Click on on ‘Check connection’.
- If the connection is profitable, it should present a inexperienced checkmark with ‘Connection profitable’.
References
Abstract
Azure Information Manufacturing facility with Managed Digital Community gives safe connections to the numerous Azure Providers like Information lake, Synapse, Key Vaults with just a few steps. With Non-public endpoint, we’re in a position to preserve all of the networking visitors on the Microsoft spine and limit it from the general public web.
We will develop this resolution to entry On-Prem databases with out using the Self-hosted integration runtime gateway. I’ve included a hyperlink within the Reference part above.
Completely happy Studying!