Devoted SQL Swimming pools Vs Serverless SQL Swimming pools In Azure Synapse Analytics
In Azure Synapse Analytics you may be incessantly crossing over a time period referred to as SQL swimming pools. It’s good to know the distinction and the working functionalities of each of them.
No requirement will likely be much like the one earlier than and the top customers may have several types of utilization for every mission. Microsoft has saved that in thoughts when designing Azure Synapse analytics and made positive finish customers can use completely different strategy to handle their compute availability for various situations. Compute and storage are the fundamental constructing blocks however in Synapse analytics each are maintained individually which allows us to scale compute independently than the info saved within the system.
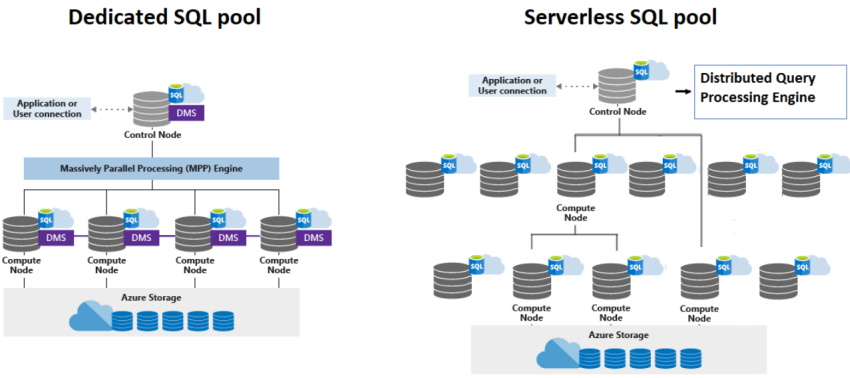
Serverless SQL Pool
A Serverless SQL Pool is an auto scale compute atmosphere wherein we will make the most of the TSQL capabilities to question the ADLS immediately. It follows a easy mannequin whereby the Serverless SQL Pool acts as compute engine and ADLS servers as a storage. All of the Synapse analytics workspace that we create will likely be having a Serverless SQL Pool endpoint as a default configuration. Serverless SQL Swimming pools are helpful in querying knowledge from ADLS (together with parquet, CSV codecs). It’s very fashionable than a devoted SQL pool for the truth that it has higher management in billing that may assist the shopper in approaching the funds and forecasting. It imposes the pay per question mannequin, and it helps the shoppers for adhoc querying. Since Serverless SQL Swimming pools don’t personal native storage all of the queries are routed to exterior endpoints and the studying from storage would possibly have an effect on question efficiency.
Devoted SQL Pool
Devoted SQL Pool is a strong MPP (Massively Parallel Processing) distributed question engine that’s apt for giant knowledge and knowledge warehousing workloads. The efficiency is predicated on DWU (Information Warehouse Models) that we choose once we create the useful resource. Minimal DWU is 100 and there will likely be one compute node for that. We are able to choose to double our DWU to 200 which is able to give us two compute nodes and double the efficiency from single node. The perfect half is we’ve the choice to pause our Devoted SQL Pool assets to droop prices and resume it once we wanted. For instance, we will course of a batch of information after which pause it as soon as it’s accomplished. Later once we want the info just for studying, we will merely scale right down to 100 DWUs as a substitute of pausing fully. Please word that the storage prices apply even once we pause the Devoted SQL Pool.
References
Microsoft official documentation