In right now’s article we’ll look into how might we run each Python and SparkSQL queries in a single pocket book workspace below the built-in Apache Spark Swimming pools to remodel the information in a single window.
Introduction
In Azure synapse analytics, a pocket book is the place you possibly can write reside code, visualize and in addition remark textual content on them. It enables you to take a look at and get the output of every cells moderately than executing your entire script. The preliminary setup may be very straightforward and you may leverage the built-in security measures which helps your knowledge keep safe. The notebooks can course of throughout a number of knowledge codecs like RAW(CSV, txt JSON), Processed(parquet, delta lake, orc), and SQL(tabular knowledge information towards spark & SQL) codecs. Aside from all of the above advantages the built-in knowledge visualization characteristic saves a whole lot of time and comes helpful when coping with subsets of knowledge.
Notebooks can assist a number of languages in several cells of a single pocket book by specifying the magic instructions in the beginning of the cell.
| Magic command | Language | Description |
| %%pyspark | Python | Execute a Python question towards Spark Context. |
| %%spark | Scala | Execute a Scala question towards Spark Context. |
| %%sql | SparkSQL | Execute a SparkSQL question towards Spark Context. |
| %%csharp | .NET for Spark C# | Execute a .NET for Spark C# question towards Spark Context. |
Steps
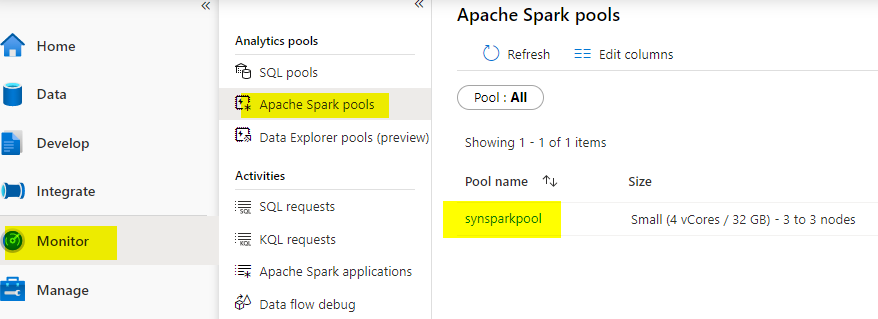
This demo will probably be run on spark pool which must be created first. Confirm if the spark pool is already obtainable in case you will have completed some labs earlier or create a brand new one. The spark pool is much like cluster that we create to run the queries, right here on this demo ‘synsparkpool’ is the apache spark pool we’re going to use for working the queries.
Go to the event tab from the left aspect and create a brand new pocket book as beneath.
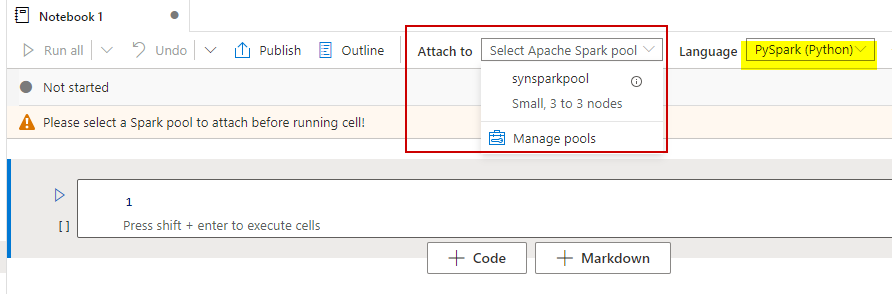
As soon as created you possibly can enter and question outcomes block by block as you’ll do in Jupyter for python queries. Make sure that the newly created pocket book is hooked up to the spark pool which we created in step one. Additionally, you will have an possibility to vary the question language between pyspark, scala, c# and sparksql from the Language dropdown possibility.
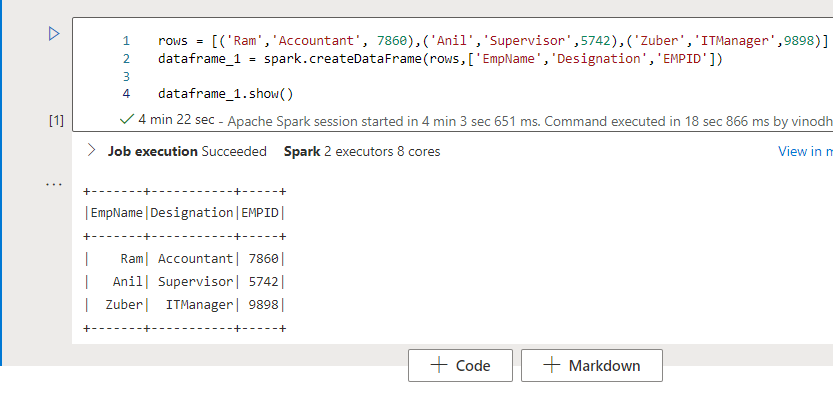
From the primary cell let’s attempt to create a PySpark knowledge body and show the outcomes. I’m going to generate some dummy knowledge for this demo. Synapse notebooks comes with Intellisense loaded which autocompletes the key phrases when you’re typing the primary letter within the cells.
Click on the play button on high left to execute the queries within the cell. Please notice that it would take a while to begin the session when executed the primary time, it took me 4.22 Minutes to finish this however it’s regular.
Now because the dataframe is created let’s save them into temp desk as you can’t reference knowledge or variables straight throughout completely different languages.
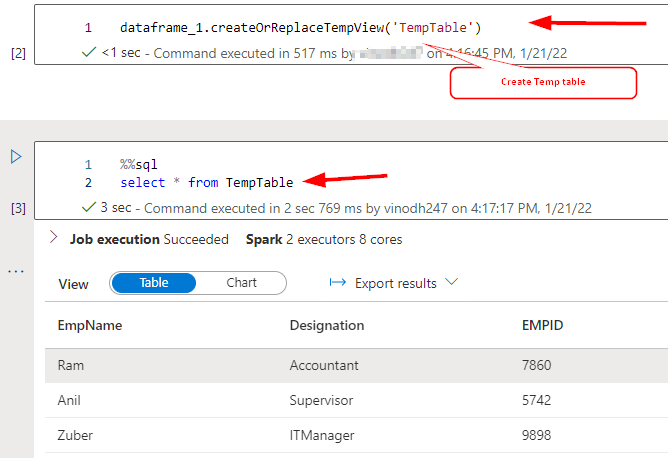
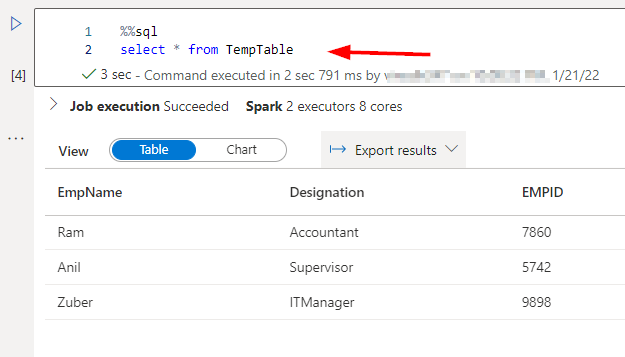
See the above picture the place we’re querying the dataframe utilizing SQL question in the identical session with one other cell which proves that it’s not restricted to solely Python or Scala solely.
Not solely with few traces of pattern knowledge, a lot of the instances you’ll have to import an entire CSV or Excel knowledge from storage location straight onto the dataframe which might later be queried by SQL. Within the subsequent step, we’ll demo the way to import an enormous quantity of knowledge.
I’m going to load the ‘Financial_Sample_Jan2021_MINI.csv’ file saved in my ADLS Gen2 storage right into a spark dataframe. For this, I’m copying the abfss path from file properties
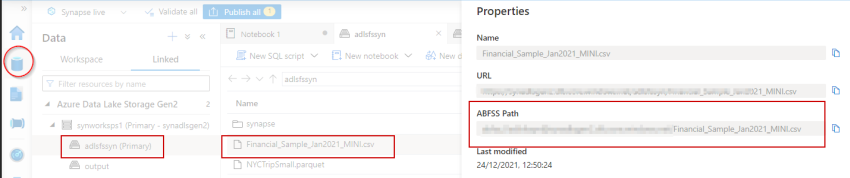
Utilizing the beneath spark question I’ve learn the CSV file knowledge into the dataframe now.
dataframe_2 = spark.learn.csv("abfss://adlsfssyn@synadlsgen2.dfs.core.home windows.web/Financial_Sample_Jan2021_MINI.csv",header=True)
dataframe_2.present()
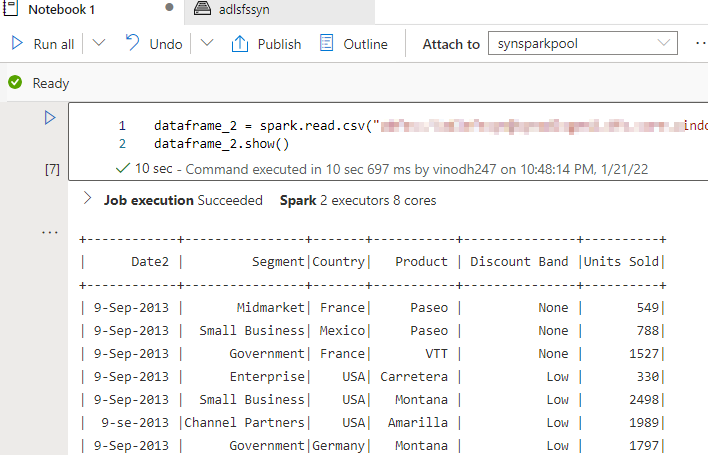
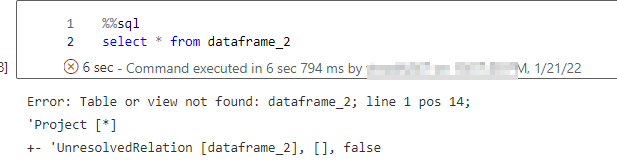
The identical dataframe can be utilized to create a temp desk or view after which queried by SQL. Please notice that when you attempt to question the dataframe straight from SQL you’re going to get the next error.
Abstract
It is a primary and easy train to indicate how synapse pocket book helps question a number of languages in a single window. One can use python to load/rework and SQL language question to question the identical knowledge from temp desk.
Reference
Microsoft official documentation