Introduction
On this publish, we are going to focus on how one can create an exterior desk and retailer the info inside your specified Azure storage in parallel utilizing TSQL statements.
What’s CETAS
CETAS or ‘Create Exterior Desk as Choose’ can be utilized with each Devoted SQL Pool and Serverless SQL Pool to create an exterior desk and parallelly export the outcomes utilizing SQL assertion to Hadoop, Azure storage blob or Azure Information Lake Storage Gen2. The information might be saved inside a folder path throughout the storage which needs to be specified. Among the vital parts of CETAS are Exterior Information Supply and Exterior File Format and I’ve written intimately about Exterior information supply in my earlier article.
I’m going to make use of the identical logical database that I created in my earlier train when creating exterior datasource and the pattern information we might be utilizing is ‘NycTaxi.parquet’ file which I’ve already uploaded to the info lake storage. Under are the entire steps together with the TSQL statements, please confer with my earlier article for an in depth rationalization of steps 1 & 2.
Step 1 – Creating Database scoped Credential
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=XXXXXxxxxxxxxxxxxxxxxxxx'
GO
Step 2 – Creating Exterior Information Supply
CREATE EXTERNAL DATA SOURCE demo
WITH ( LOCATION = 'https://synadlsgen2.blob.core.home windows.internet/output',
CREDENTIAL=[ADLS_credential])
Step 3 – Creating Exterior File Format
Exterior file format defines the format of the exterior information that you’re going to entry. It’s going to specify the structure of the kind of information that’s going to be referenced by the exterior desk. In azure synapse presently solely two file codecs are supported,
- Delimited Textual content
- Parquet
I’ve used the second for the reason that demo file NycTaxi we’re going to use is parquet file format. Default snappycodec compression choice has been used for this.
CREATE EXTERNAL FILE FORMAT ParquetFileFormat
WITH (
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Step 4 – Creating Schema
The subsequent step is creating the schema as all of the exterior desk and different database objects might be contained throughout the Schema.
CREATE SCHEMA nyctaxi
Step 5 – Creating Exterior Desk
It’s now time to create the exterior desk which is the target of this demo. Given under is the question which creates exterior desk and the choose assertion from which it pulls the info from the parquet file. Now all of it seems to be good, let’s run it.
You’ll be able to see that the choose assertion has been included when creating the exterior desk as I’m loading the aggregated outcomes from the choose assertion instantly onto the desk.
CREATE EXTERNAL TABLE nycdemotable
WITH (
LOCATION = 'synadlsgen2/output',
DATA_SOURCE = demo,
FILE_FORMAT = ParquetFileFormat
)
AS
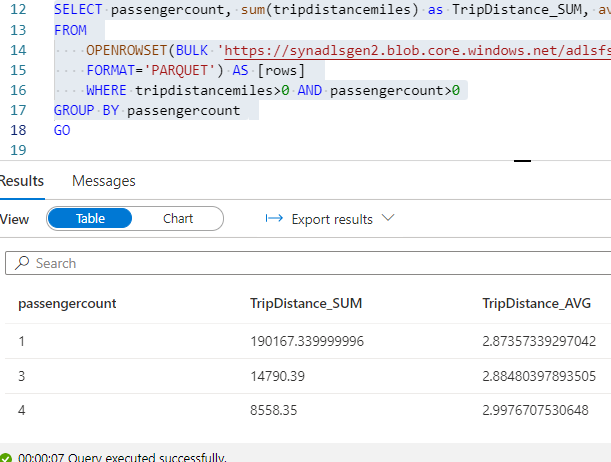
SELECT passengercount, sum(tripdistancemiles) as TripDistance_SUM, avg(tripdistancemiles) as TripDistance_AVG
FROM
OPENROWSET(BULK 'https://synadlsgen2.blob.core.home windows.internet/adlsfssyn/NYCTripSmall.parquet',
FORMAT='PARQUET') AS [rows]
WHERE tripdistancemiles>0 AND passengercount>0
GROUP BY passengercount
GO
I’ve run the choose question alone to confirm the desk rely and output and if the parquet out there in ADLS is accessible.
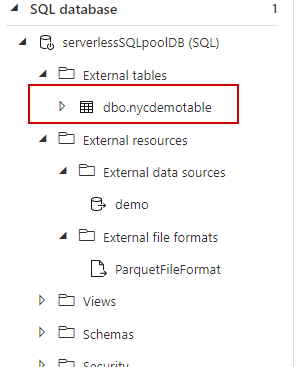
We may see the exterior desk is now created. Proper click on and choose prime 100 rows to see the outcomes.
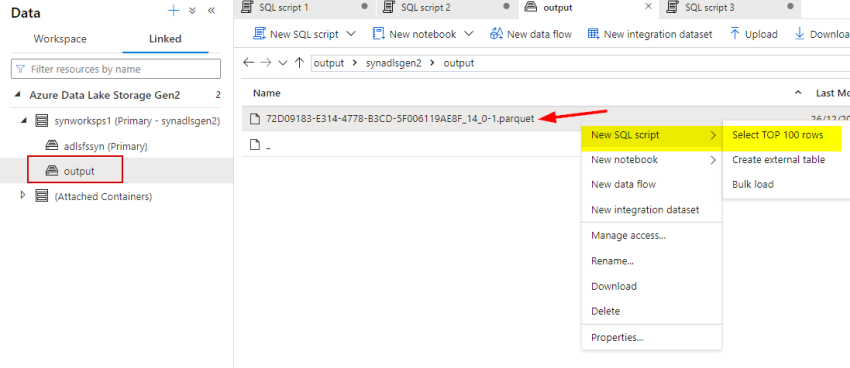
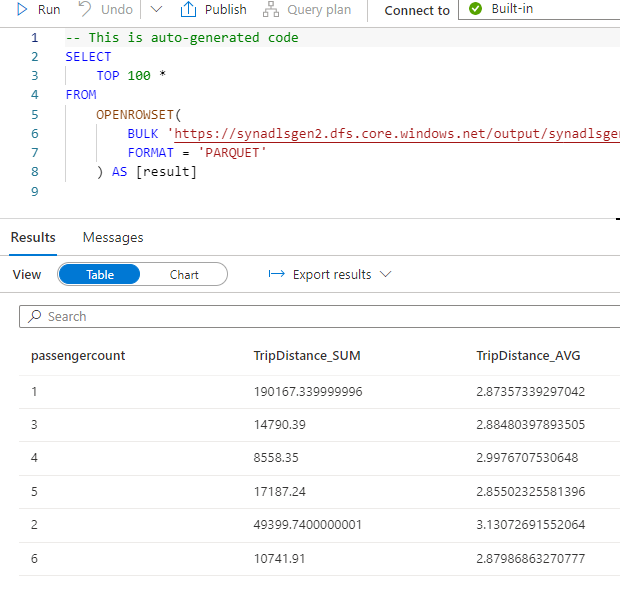
Now go to the ADLS storage to examine if the output from choose has been saved into file format as nicely.
Abstract
This text explains what’s CETAS in synapse and the way may we put it to use for parallel processing on totally different file codecs. This works greatest when learning the earlier article which explains base ideas of what we used right here.
Reference
Microsoft official docs