Azure Information Manufacturing unit
On this article, we’ll study datasets, the JSON format they’re outlined in and their utilization in Azure Information Manufacturing unit pipelines. The article incorporates the pattern of dataset in Information manufacturing unit with its properties nicely described. We additionally be taught in regards to the sorts of Datasets and the info shops which can be supported by the Information Manufacturing unit is listed. The instruments to create datasets are listed too and the variations of the variations of Information Manufacturing unit are nicely differentiated in tabular format. Furthermore, the naming guidelines are additionally mentioned intimately and a quick introduction to CI/CD for Azure Information manufacturing unit
A number of pipelines are supported by the info manufacturing unit. A pipeline might be outlined because the logical grouping of various actions which all collectively carry out a job the place the actions within the pipeline outline the actions that must be carried out on the info.
Dataset might be understood because the named view of the info which refers back to the information that’s for use for the actions as inputs and outputs. Datasets are accountable to determine the info which can be current in multitudes of information shops as an example, tables, recordsdata, paperwork, and folders. To know deeper, we will take the reference of the Azure Blob. The Azure Blob dataset specifies the folder and blob container within the Blob storage of Azure by means of which information is learn by the exercise.
Linked Service must be created earlier than making a dataset to be able to hyperlink information retailer to the info manufacturing unit. Linked providers outline the connection info that are wanted to hook up with the exterior sources for the Information Manufacturing unit. Storage account are linked to the info manufacturing unit by means of the linked service of Azure Storage. The enter blobs that should be processed are current within the Azure Storage account and the folder and container are represented by the Azure Blob dataset.
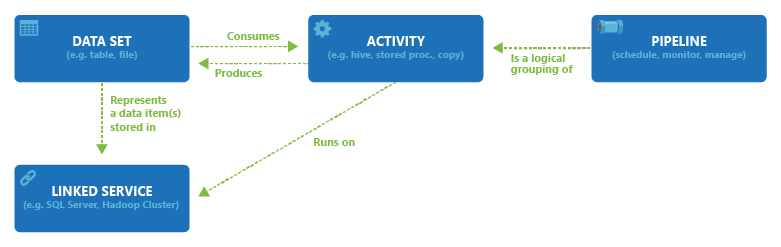
The connection between dataset, exercise, pipeline, and linked service current within the Information Manufacturing unit is proven within the diagram under,
Exercise
Exercise refers back to the job that’s carried out on the info. The actions are used contained in the Azure Manufacturing unit Pipelines (ADF). The ADF pipelines are mainly a gaggle of a number of actions. For Occasion, Creating ADF pipeline to carry out ETL permits a number of actions corresponding to extracting information, remodeling information and loading information to information warehouse. Examples of actions are hive, saved proc, copy, map scale back, and so forth.
Hive – The Hive is an HDInsight exercise which executes Hive queries based mostly on HDInsight cluster on Linux and home windows that’s used to investigate and course of structured information.
Saved Proc – Saved Process in information manufacturing unit pipeline helps to invoke a SQL Server Saved process. Azure SQL Database, Azure Synapse Analytics, SQL Server Database are a number of the information shops the place saved proc can be utilized.
Copy – The Copy exercise helps copy the info from supply location to the vacation spot location. Quite a few information retailer places corresponding to NoSQL, Information, Azure Storage and Azure DBs are supported by Azure.
Dataset in Information Manufacturing unit
The JSON code under defines the dataset within the Information Manufacturing unit.
{
"title": "<title of dataset>",
"properties": {
"kind": "<kind of dataset: DelimitedText, AzureSqlTable and so on...>",
"linkedServiceName": {
"referenceName": "<title of linked service>",
"kind": "LinkedServiceReference",
},
"schema": [],
"typeProperties": {
"<kind particular property>": "<worth>",
"<kind particular property 2>": "<worth 2>",
}
}
}
The properties of the above JSON are nicely described within the desk under.
| Property | Description | Required |
| title | The Identify of the Dataset. | Sure |
| kind | It’s the kind of Dataset. One of many sorts supported by the Information Manufacturing unit should be specified. | Sure |
| schema | The bodily information kind and form is represented by the Schema of the Dataset. | No |
| typeProperties | Every kind has different kind properties. | Sure |
Kinds of Datasets
Multitudes of numerous sorts of datasets are supported by the Azure Information Manufacturing unit which will depend on the info shops which can be for use. Connector Overview hearken to the info shops which can be supported by the Information Manufacturing unit.
The next JSON reveals the DelimitedText which is ready for the Delimited Textual content dataset.
{
"title": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"kind": "LinkedServiceReference"
},
"annotations": [],
"kind": "DelimitedText",
"typeProperties": {
"location": {
"kind": "AzureBlobStorageLocation",
"fileName": "enter.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "",
"quoteChar": """
},
"schema": []
}
}
The checklist of information shops which can be supported by the Information Manufacturing unit is as follows,
| Class | Information Retailer |
| Azure | Azure Blob Storage Azure Information Lake Storage Gen1 Azure SQL Database Azure Synapse Analytics Azure Cosmos DB (SQL API) Azure Desk Storage Azure Cognitive Search Index |
| Databases | SQL Server MySQL PostgreSQL Oracle Amazon Redshift DB2 SAP Enterprise Warehouse SAP HANA Sybase Teradata |
| NoSQL | Cassandra MongoDB |
| File | FTP File System Amazon S3 HDFS SFTP |
| Others | Generic HTTP Generic OData Generic ODBC Internet Desk (desk from HTML) Salesforce |
Be taught extra about Information Transformation utilizing Azure Information Manufacturing unit from this video,
Creating Datasets
Datasets might be created utilizing instruments or SDKs corresponding to Azure Useful resource Supervisor Template, Azure Portal, Powershell, REST API, and .NET API.
Furthermore, there are just a few variations between the Model 1 Datasets and the Present Model Datasets of Information manufacturing unit.
| Information Manufacturing unit Model 1 Datasets | Information Manufacturing unit Present Model Datasets |
| Use of exterior property. | Changed by Set off. |
| Use of Coverage and Availability properties. | Begin time will depend on triggers for pipelines. |
| Scoped Datasets are supported. | Scoped Datasets are deprecated. |
Naming Guidelines
The varied naming guidelines for Information Manufacturing unit artifacts are listed within the desk under.
| Identify | Uniqueness of Identify | Checks for Validation |
| Information Manufacturing unit | Case-insensitive. Eg. Df and DF discuss with the identical information manufacturing unit. The names are distinctive throughout Azure platform. | One Azure Subscription is tied to just one information manufacturing unit. The initials of object names needs to be quantity or a letter and solely accepts alpha numeric values and the sprint (-) character. The sprint (-) character should be between an alphanumeric character. The permission of consecutive sprint is null and void. Solely 3-63 characters lengthy names are accepted. |
| Linked providers/Datasets/Pipelines/Information Flows | Case-insensitive. Eg. ls and LS discuss with the identical linked service or datasets or pipeline. It’s distinctive solely inside a knowledge manufacturing unit. | Should be initialized with letter for the thing title. “.”, “+”, “?”, “/”, “<”, ”>”,”*”,”%”,”&”,”:”,”” – These characters a unaccepted. The sprint (-) character will not be accepted too. |
| Integration Runtime | Case-insensitive. Eg. lR and ir discuss with the combination runtime. | Can include alphanumeric values and the sprint (-) character. Should include an alphanumeric worth within the first and final character. The sprint (-) character should be between an alphanumeric character. The permission of consecutive sprint is null and void. |
| Information Movement Transformations | Case-insensitive. Eg. lR and ir discuss with the identical Information Movement transformations. It’s distinctive solely inside a knowledge movement. | Can solely include alphanumeric values. Should be initialized with an alphabet character. |
| Useful resource Group | Case-insensitive. Eg. RG and rg discuss with the identical useful resource group. The names are distinctive throughout Azure platform. | |
| Pipeline Parameters and Variable | Case-insensitive. Eg. PV and pv discuss with the identical variable and pipeline parameters. | Attributable to backward compatibility causes, the validation test on parameter names and variable names is proscribed to uniqueness. |
CI/ CD in Azure Information Manufacturing unit
Steady Integration refers back to the follow of testing each change that’s made to the codebase routinely as early as doable and follows the testing that happen throughout steady integration and thus pushes the modifications to the manufacturing system or staging.
Right here, within the Azure Information Manufacturing unit, CI/CD refers to shifting of the Information Manufacturing unit pipelines from one specific atmosphere corresponding to growth, testing and manufacturing to a different. Azure Useful resource Supervisor templates is utilized by the Azure Information Manufacturing unit to be able to retailer numerous ADP entities like pipelines, datasets and information movement’s configuration.
There are mainly two instructed strategies for selling the info manufacturing unit to one other atmosphere.
- Utilizing Information manufacturing unit UX with Azure Useful resource Supervisor to Manually add the Useful resource Supervisor Template
- Utilizing integration of Information Manufacturing unit with Azure Pipeline to make Automated Deployment
Conclusion
Thus, on this article, we realized about Azure Datasets with an in depth understanding of Azure Information Manufacturing unit, its pipelines, the pattern of dataset in Information Manufacturing unit with the properties of the JSON pattern. Then we learnt in regards to the sorts of Datasets and a pattern DelimitedText dataset. We additionally learnt in regards to the variations within the variations of Datasets of Information Manufacturing unit. We then learnt in regards to the Naming Guidelines for the Information Manufacturing unit artifacts, the distinctiveness of the title and the validation guidelines. Lastly, we learnt about CI/CD in Azure Information Manufacturing unit briefly.