“Once I first kicked off this Advancing Reliability weblog collection in my publish final July, I highlighted a number of initiatives underway to maintain bettering platform availability, as a part of our dedication to supply a trusted set of cloud providers. One space I discussed was fault injection, by means of which we’re more and more validating that programs will carry out as designed within the face of failures. At present I’ve requested our Principal Program Supervisor on this house, Chris Ashton, to shed some gentle on these broader ‘chaos engineering’ ideas, and to stipulate Azure examples of how we’re already making use of these, along with stress testing and artificial workloads, to enhance software and repair resilience.” – Mark Russinovich, CTO, Azure
Growing large-scale, distributed purposes has by no means been simpler, however there’s a catch. Sure, infrastructure is offered in minutes due to your public cloud, there are numerous language choices to select from, swaths of open supply code out there to leverage, and considerable elements and providers within the market to construct upon. Sure, there are good reference guides that assist give a leg up in your resolution structure and design, such because the Azure Properly-Architected Framework and different sources within the Azure Structure Middle. However whereas software improvement is less complicated, there’s additionally an elevated threat of impression from dependency disruptions. Nonetheless uncommon, outages past your management may happen at any time, your dependencies may have incidents, or your key providers/programs may develop into sluggish to reply. Minor disruptions in a single space might be magnified or have longstanding negative effects in one other. These service disruptions can rob developer productiveness, negatively have an effect on buyer belief, trigger misplaced enterprise, and even impression a company’s backside line.
Trendy purposes, and the cloud platforms upon which they’re constructed, should be designed and repeatedly validated for failure. Builders must account for identified and unknown failure circumstances, purposes and providers should be architected for redundancy, algorithms want retry and back-off mechanisms. Programs should be resilient to the eventualities and circumstances attributable to rare however inevitable manufacturing outages and disruptions. This publish is designed to get you desirous about how finest to validate typical failure circumstances, together with examples of how we at Microsoft validate our personal programs.
Resilience
Resilience is the power of a system to fail gracefully within the face of—and ultimately recuperate from—disruptive occasions. Validating that an software, service, or platform is resilient is equally as vital as constructing for failure. It’s straightforward and tempting to validate the reliability of particular person elements in isolation and infer that the complete system can be simply as dependable, however that may very well be a mistake. Resilience is a property of a whole system, not simply its elements. To know if a system is actually resilient, it’s best to measure and perceive the resilience of the complete system within the surroundings the place it would run. However how do you do that, and the place do you begin?
Chaos engineering and fault injection
Chaos engineering is the follow of subjecting a system to the real-world failures and dependency disruptions it would face in manufacturing. Fault injection is the deliberate introduction of failure right into a system with the intention to validate its robustness and error dealing with.
By way of the usage of fault injection and the applying of chaos engineering practices typically, architects can construct confidence of their designs – and builders can measure, perceive, and enhance the resilience of their purposes. Equally, Web site Reliability Engineers (SREs) and actually anybody who holds their wider groups accountable on this house can be sure that their service stage targets are inside goal, and monitor system well being in manufacturing. Likewise, operations groups can validate new {hardware} and datacenters earlier than rolling out for buyer use. Incorporation of chaos strategies in launch validation offers everybody, together with administration, confidence within the programs that their group is constructing.
All through the event course of, as you might be hopefully doing already, check early and check usually. As you put together to take your software or service to manufacturing, comply with regular testing practices by including and operating unit, purposeful, stress, and integration checks. The place it is smart, add check protection for failure instances, and use fault injection to substantiate error dealing with and algorithm habits. For even better impression, and that is the place chaos engineering actually comes into play, increase end-to-end workloads (comparable to stress checks, efficiency benchmarks, or an artificial workload) with fault injection. Begin in a pre-production check surroundings earlier than performing experiments in manufacturing, and perceive how your resolution behaves in a protected surroundings with an artificial workload earlier than introducing potential impression to actual buyer site visitors.
Wholesome use of fault injection in a validation course of would possibly embody a number of of the next:
- Advert hoc validation of recent options in a check surroundings:
A developer may get up a check digital machine (VM) and run new code in isolation. Whereas executing present purposeful or stress checks, faults may very well be injected to dam community entry to a distant dependency (comparable to SQL Server) to show that the brand new code handles the situation accurately. - Automated fault injection protection in a CI/CD pipeline, together with deployment or resiliency gates:
Present end-to-end situation checks (comparable to integration or stress checks) might be augmented with fault injection. Merely insert a brand new step after regular execution to proceed operating or run once more with some faults utilized. The addition of faults can discover points that will usually not be discovered by the checks or to speed up discovery of points that could be discovered ultimately. - Incident repair validation and incident regression testing:
Fault injection can be utilized along with a workload or guide execution to induce the identical circumstances that brought on an incident, enabling validation of a selected incident repair or regression testing of an incident situation. - BCDR drills in a pre-production surroundings:
Faults that trigger database failover or take storage offline can be utilized in BCDR drills, to validate that programs behave appropriately within the face of those faults and that information will not be misplaced throughout any failover checks. - Sport days in manufacturing:
A ‘sport day’ is a coordinated simulation of an outage or incident, to validate that programs deal with the occasion accurately. This usually consists of validation of monitoring programs in addition to human processes that come into play throughout an incident. Groups that carry out sport days can leverage fault injection tooling, to orchestrate faults that signify a hypothetical situation in a managed method.
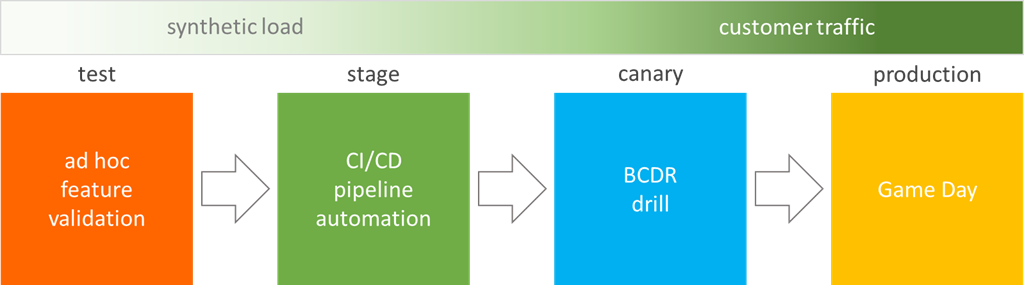
Typical launch pipeline
This determine reveals a typical launch pipeline, and alternatives to incorporate fault injection:

An funding in fault injection can be extra profitable whether it is constructed upon a couple of foundational elements:
- Coordinated deployment pipeline.
- Automated ARM deployments.
- Artificial runners and artificial end-to-end workloads.
- Monitoring, alerting, and livesite dashboards.
With this stuff in place, fault injection might be built-in within the deployment course of with little to no further overhead – and can be utilized to gate code move on its approach to manufacturing.
Localized rack energy outages and gear failures have been discovered as single factors of failure in root trigger evaluation of previous incidents. Studying {that a} service is impacted by, and never resilient to, one among these occasions in manufacturing is a timebound, painful, and costly course of for an on-call engineer. There are a number of alternatives to make use of fault injection to validate resilience to those failures all through the discharge pipeline in a managed surroundings and timeframe, which additionally offers extra alternative for the code writer to guide an investigation of points uncovered. A developer who has code adjustments or new code can create a check surroundings, deploy the code, and carry out advert hoc experiments utilizing purposeful checks and instruments with faults that simulate taking dependencies offline – comparable to killing VMs, blocking entry to providers, or just altering permissions. In a staging surroundings, injection of comparable faults might be added to automated end-to-end and integration checks or different artificial workloads. Check outcomes and telemetry can then be used to find out impression of the faults and in contrast in opposition to baseline efficiency to dam code move if essential.
In a pre-production or ‘Canary’ surroundings, automated runners can be utilized with faults that once more block entry to dependencies or take them offline. Monitoring, alerting, and livesite dashboards can then be used to validate that the outages had been noticed in addition to that the system reacted and compensated for the problem—that it demonstrated resilience. On this similar surroundings, SREs or operations groups may carry out enterprise continuity/catastrophe restoration (BCDR) drills, utilizing fault injection to take storage or databases offline and as soon as once more monitoring system metrics to validate resilience and information integrity. These similar Canary actions may also be carried out in manufacturing the place there’s actual buyer site visitors, however doing so incurs a better chance of impression to clients so it is suggested solely to do that after leveraging fault injection earlier within the pipeline. Establishing these practices and incorporating fault injection right into a deployment pipeline permits systematic and managed resilience validation which permits groups to mitigate points, and enhance software reliability, with out impacting finish clients.
Fault injection at Microsoft
At Microsoft, some groups incorporate fault injection early of their validation pipeline and automatic check passes. Totally different groups run stress checks, efficiency benchmarks, or artificial workloads of their automated validation gates as regular and a baseline is established. Then the workload is run once more, this time with faults utilized – comparable to CPU strain, disk IO jitter, or community latency. Workload outcomes are monitored, telemetry is scanned, crash dumps are checked, and Service Degree Indicators (SLIs) are in contrast with Service Degree Goals (SLOs) to gauge the impression. If outcomes are deemed a failure, code could not move to the subsequent stage within the pipeline.
Different Microsoft groups use fault injection in common Enterprise Continuity, Catastrophe Restoration (BCDR) drills, and Sport Days. Some groups have month-to-month, quarterly, or half-yearly BCDR drills and use fault injection to induce a catastrophe and validate each the restoration course of in addition to the alerting, monitoring and stay website processes. That is usually finished in a pre-production Canary surroundings earlier than being utilized in manufacturing itself with actual buyer site visitors. Some groups additionally perform Sport Days, the place they give you a hypothetical situation, comparable to replication of a previous incident, and use fault injection to assist orchestrate it. Faults, on this case, could be extra damaging—comparable to crashing VMs, turning off community entry, inflicting database failover, or simulating a whole datacenter going offline. Once more, regular stay website monitoring and alerting are used, so your DevOps and incident administration processes are additionally validated. To be sort to all concerned, these actions are usually carried out throughout enterprise hours and never in a single day or over a weekend.
Our operations groups additionally use fault injection to validate new {hardware} earlier than it’s deployed for buyer use. Drills are carried out the place the facility is shut off to a rack or datacenter, so the monitoring and backup programs might be noticed to make sure they behave as anticipated.
At Microsoft, we use chaos engineering ideas and fault injection strategies to extend resilience, and confidence, within the merchandise we ship. They’re used to validate the purposes we ship to clients, and the providers we make out there to builders. They’re used to validate the underlying Azure platform itself, to check new {hardware} earlier than it’s deployed. Individually and collectively, these contribute to the general reliability of the Azure platform—and improved high quality in our providers all up.
Unintended penalties
Keep in mind, fault injection is a strong instrument and ought to be used with warning. Safeguards ought to be in place to make sure that faults launched in a check or pre-production surroundings won’t additionally have an effect on manufacturing. The blast radius of a fault situation ought to be contained to attenuate impression to different elements and to finish clients. The power to inject faults ought to have restricted entry, to forestall accidents and forestall potential use by hackers with malicious intent. Fault injection can be utilized in manufacturing, however plan fastidiously, check first in pre-production, restrict the blast radius, and have a failsafe to make sure that an experiment might be ended abruptly if wanted. The 1986 Chernobyl nuclear accident is a sobering instance of a fault injection drill gone fallacious. Watch out to insulate your system from unintended penalties.
Chaos as a service?
As Mark Russinovich talked about on this earlier weblog publish, our objective is to make native fault injection providers out there to clients and companions to allow them to carry out the identical validation on their very own purposes and providers. That is an thrilling house with a lot potential to enhance cloud service reliability and scale back the impression of uncommon however inevitable disruptions. There are numerous groups doing numerous attention-grabbing issues on this house, and we’re exploring how finest to convey all these disparate instruments and faults collectively to make our lives simpler—for our inner builders constructing Azure providers, for built-on-Azure providers like Microsoft 365, Microsoft Groups, and Dynamics, and ultimately for our clients and companions to make use of the identical tooling to wreak havoc on (and in the end enhance the resilience of) their very own purposes and options.